Xception 的主要特点是 Depthwise Separable Convolutions, Xception 在多个数据集上并没有比 Inception V3 好很多的结果,但是,Xception 中 Depthwise Separable Convolutions 的做法在最近的一些高效模型中被广泛使用。
与 vgg 不同的是,Inception 系列的模型,包括后来的 resnet 等,做法都是先设计几个比较高效的 building block, 然后串联起很多个 building block 来构建整个网络模型。
在 CNN 中最常使用的卷积是 3 维卷积,其中 2 维是空间信息,即高和宽信息,另外 1 维 是 channel 信息。因此,一个卷积核同时要搞定 cross channel 的信息又要搞定 spatial 信息。Inception 中已经注意到了这个问题,因此,在 Inception 中,首先使用一个 \(1 \times 1\) 的卷积来处理 cross channel 的信息,把一个比较大的 feature map 映射到多个较小的 output, 然后在这些较小的 output 上使用 \(3 \times 3 \) 的卷积和 \(5 \times 5\) 的卷积来进一步处理 (注意,这里的卷积核仍是 3 维的). Inception 认为,cross channel correlation 信息和 spatial correlation 信息之间是没有关系的,因此,这两个部分应该尽量解耦。如下图。
上图中,如果去掉 avg pooling 这个 tower, 然后精简一下可以变成下面这个版本:
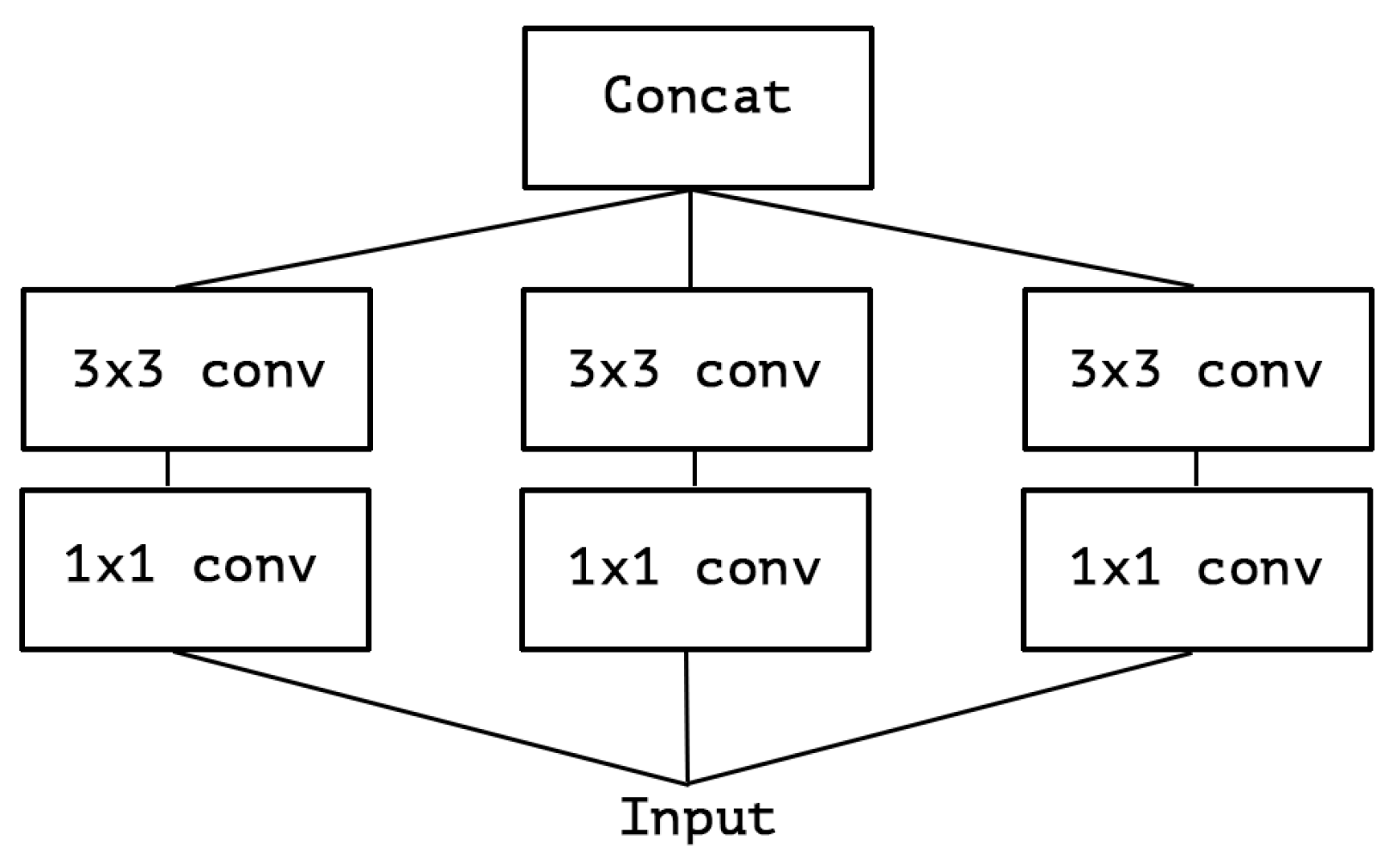
上面这个简化版的 Inception 的等价版本如下:
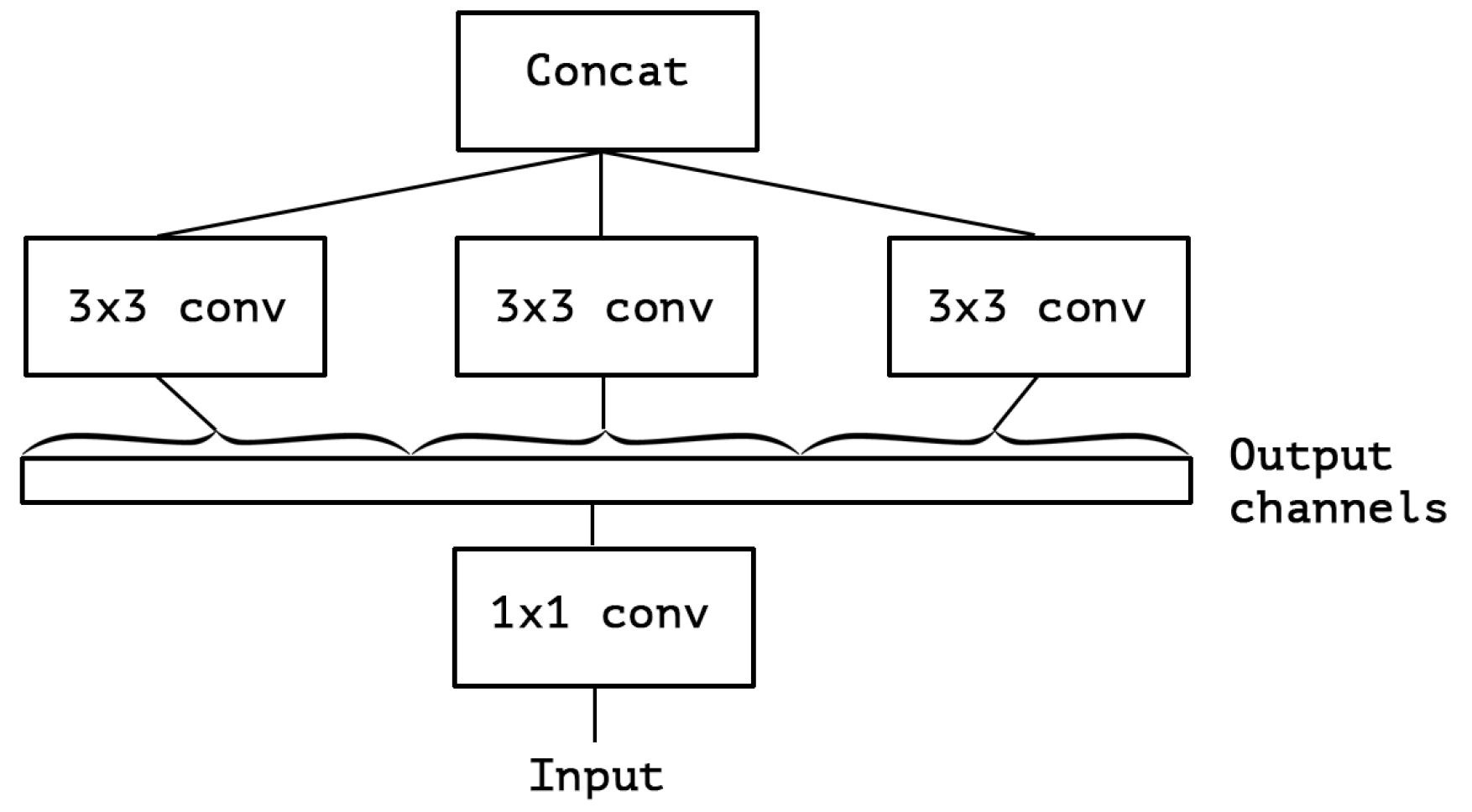
即多个 \(1 \times 1\) 的卷积可以用一个 \(1 \times 1\) 的卷积来完成。
现在这个版本,通过 \(1 \times 1\) 的卷积来处理 cross channel correlation 信息,但是,后面的 \(3 \times 3\) 的卷积仍然是 3 维的,也就是说,这里的 \(3 \times 3\) 的卷积仍然同时处理和 cross channel correlation 信息和 spatial correlation 信息,因此,有没有可能进一步解耦 \(3 \times 3\) 的卷积操作呢?这就是 Xception 做的事情。如下图:
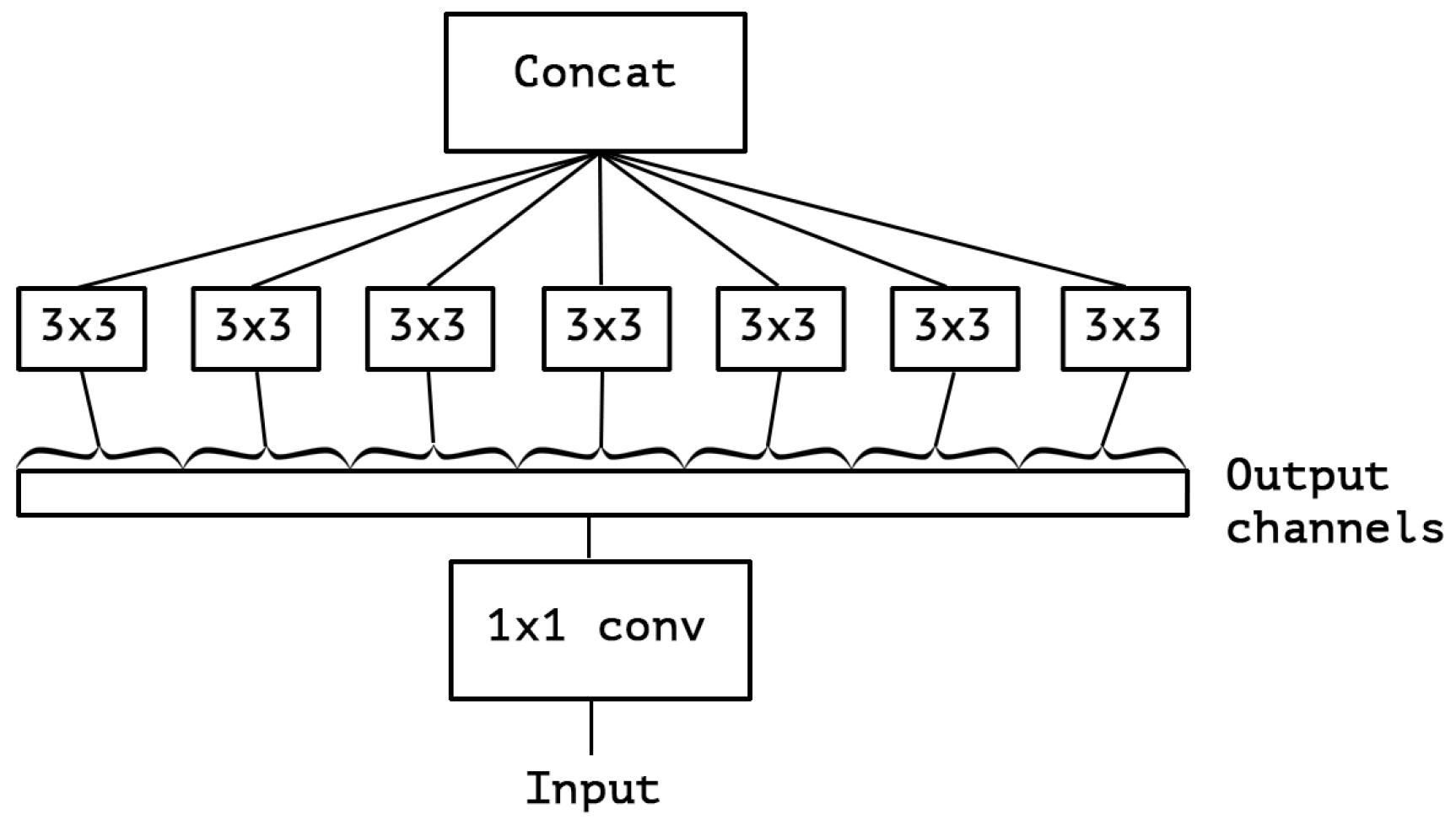
具体来说,Xception 的做法是,首先是用 \(1 \times 1\) 的卷积来处理 cross channel correlation, 然后,对出输出的每一个 channel, 使用 \(3 \times 3 \) 的卷积核来处理 spatial correlation, 然后把输出 concat 起来。
注意 Xception 和 depthwise separable convolution 的区别:
- 操作顺序不同,Xception 先做 \(1 \times 1\) 的 convolution, 然后是 channel-wise spatial convolution 操作,depthwise separable convolution 恰好相反。
- Xception 在每一次 convolution 操作之后都要进行非线性变换,例如 ReLU, depthwise separable convolution 没有非线性变换。