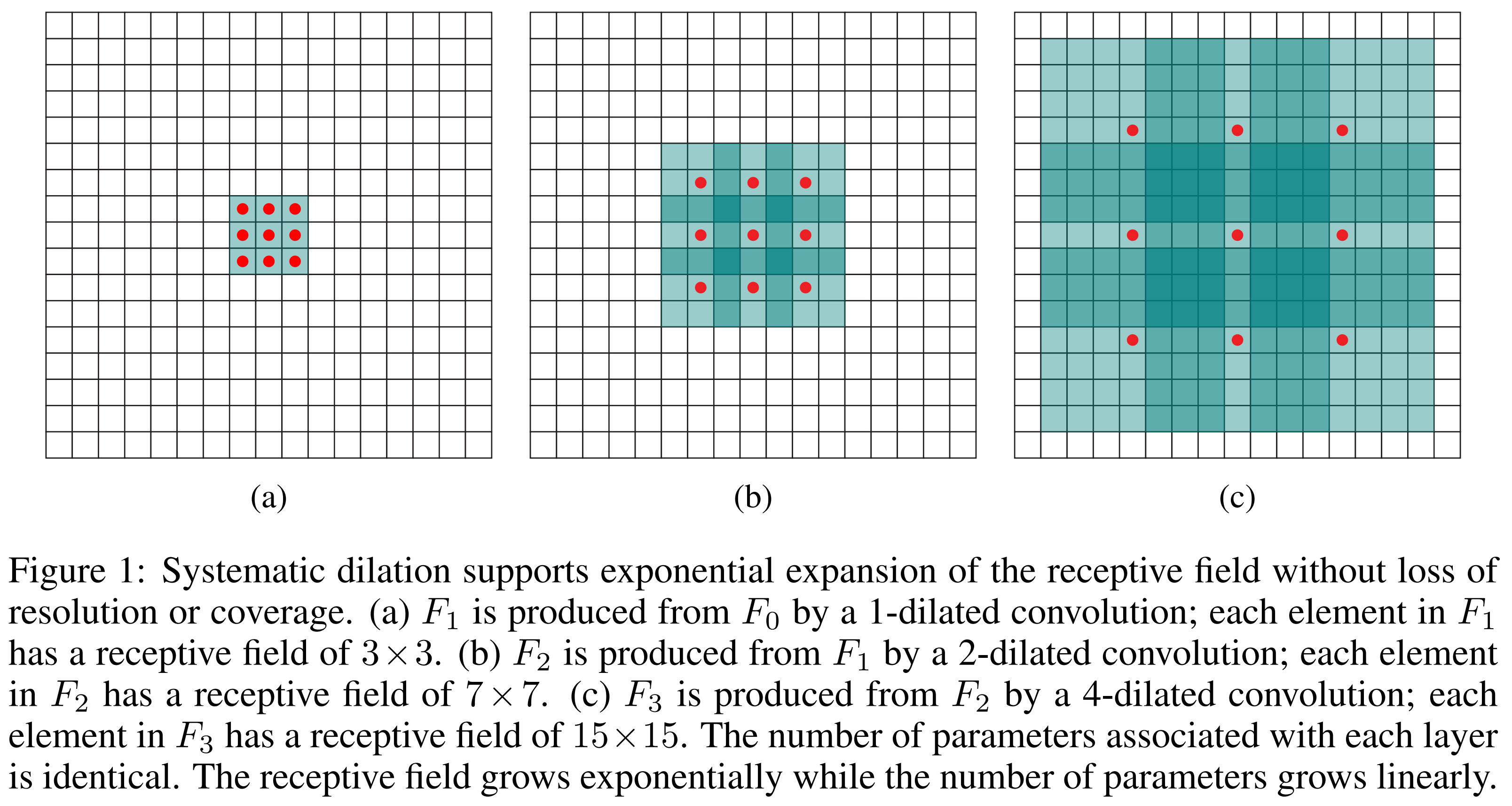
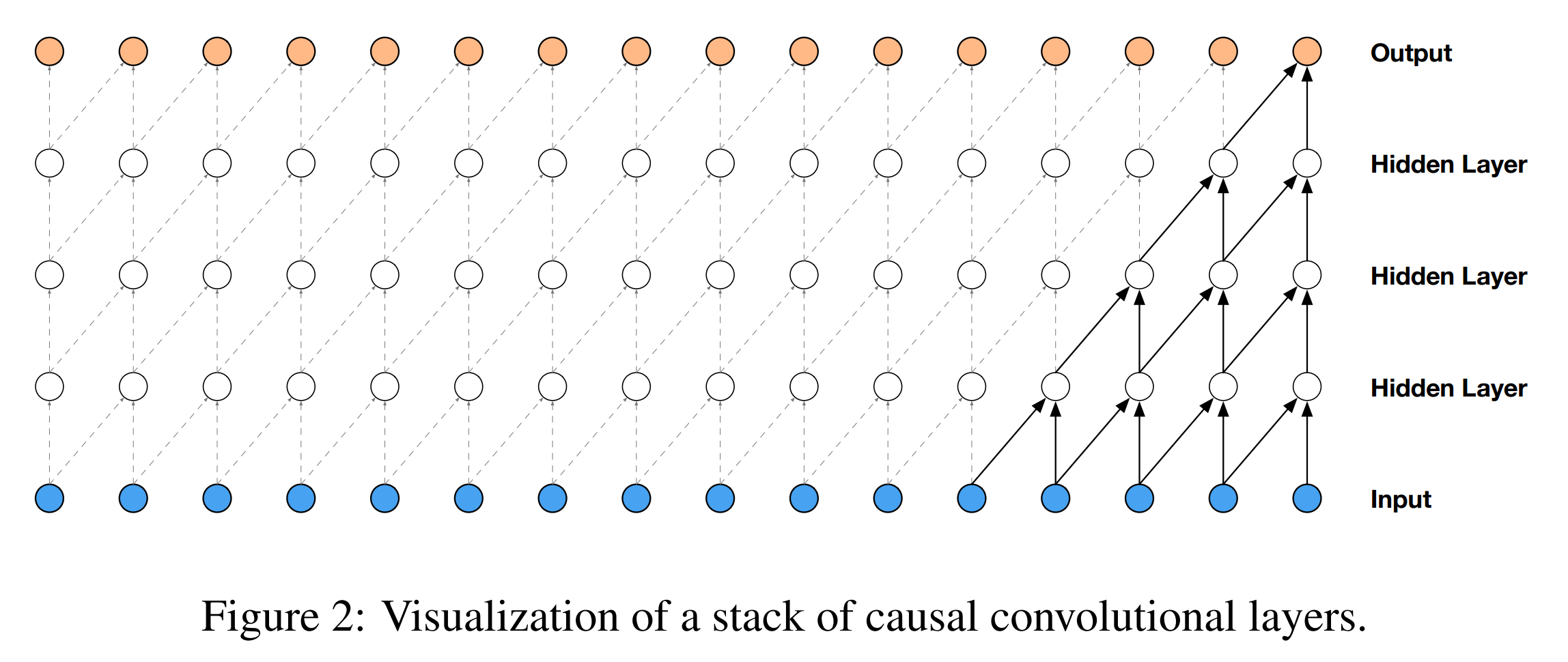
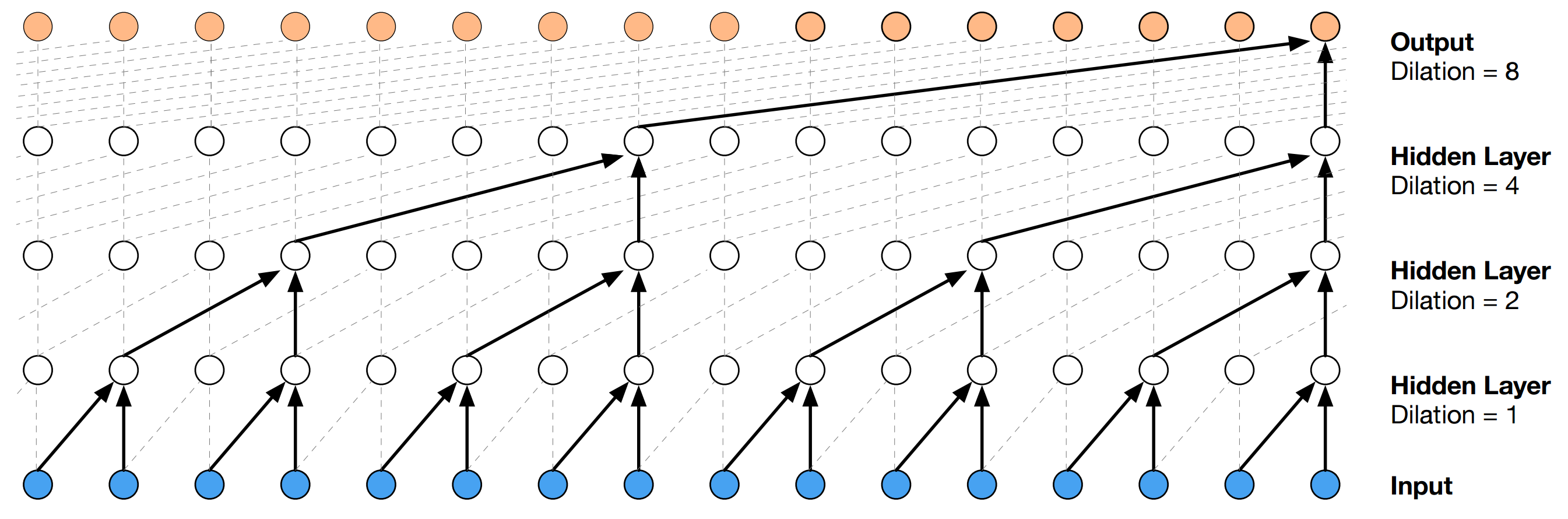
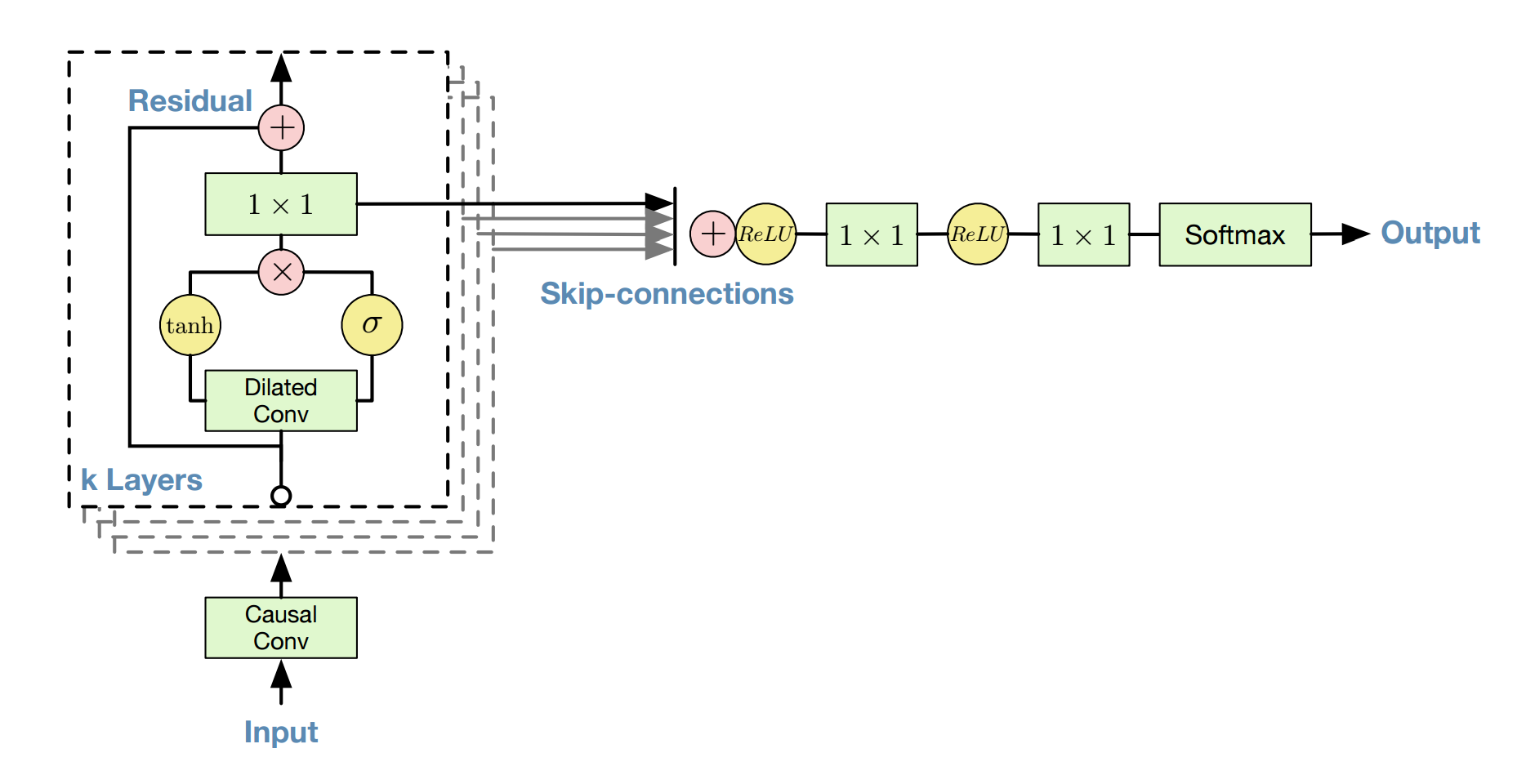
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
| import mxnet as mx
import numpy as np
import multiprocessing
from scipy.ndimage.interpolation import shift
def causal_layer(data=None, name="causal"):
assert isinstance(data, mx.symbol.Symbol)
zero = mx.symbol.Variable(name=name+"-zero")
concat = mx.symbol.Concat(*[data, zero], dim=3, name=name+"-concat")
causal = mx.symbol.Convolution(data=concat, kernel=(1, 2), stride=(1, 1), num_filter=16, name=name)
return causal
def residual_block(data=None, kernel=(1, 2), dilate=None, num_filter=16, name=None, stride=(1, 1), output_channel=None):
assert name is not None
assert dilate is not None
assert output_channel is not None
assert isinstance(data, mx.symbol.Symbol)
zero = mx.symbol.Variable(name=name+"-zero")
concat = mx.symbol.Concat(*[data, zero], dim=3, name=name+"-concat")
conv_filter = mx.symbol.Convolution(data=concat, kernel=kernel, stride=stride, dilate=dilate, num_filter=num_filter, name=name+"conv-filter")
conv_gate = mx.symbol.Convolution(data=concat, kernel=kernel, stride=stride, dilate=dilate, num_filter=num_filter, name=name+"conv-gate")
output_filter = mx.symbol.Activation(data=conv_filter, act_type="tanh")
output_gate = mx.symbol.Activation(data=conv_gate, act_type="sigmoid")
output = output_filter * output_gate
out = mx.symbol.Convolution(data=output, kernel=(1, 1), num_filter=output_channel)
return out+data, out
class DataBatch(object):
def __init__(self, data, label):
self.data = data
self.label = label
class DataIter(mx.io.DataIter):
def __init__(self, batch_size, length, names, shape):
self.provide_data = [(k, v) for k, v in shape.iteritems()]
self.provide_label = [("softmax_label", (batch_size, length))]
self.cur_batch = 0
self.num_batch = len(names)/batch_size
self.batch_size = batch_size
self.length = length
self.names = names
self.q = multiprocessing.Queue(maxsize=4)
self.pws = [multiprocessing.Process(target=self.get_batch) for i in xrange(4)]
for pw in self.pws:
pw.daemon = True
pw.start()
def reset(self):
self.cur_batch = 0
def __iter__(self):
return self
def __next__(self):
return self.next()
def get_batch(self):
while True:
data_all = np.empty(shape=(self.batch_size, 1, 1, self.length))
label_all = np.empty(shape=(self.batch_size, self.length))
mx_data = []
mx_label = []
idx = 0
while idx < self.batch_size:
name = random.choice(self.names)
audio, _ = librosa.load(name, sr=16000, mono=True)
if audio.shape[0] < self.length:
continue
audio = audio[:self.length]
magnitude = 1.0*np.log(1+255*np.abs(audio))/np.log(1.0+255)
signal = np.sign(audio) * magnitude
audio = ((signal+1)/2.0*255+0.5).astype(np.int32)
label = shift(audio, -1, cval=0)
data_all[idx, :, :, :] = audio
label_all[idx, :] = label
idx += 1
for k, v in shape.iteritems():
if "input" in k:
data = mx.nd.array(np.reshape(data_all, v))
else:
data = mx.nd.array(np.zeros(shape=v))
mx_data.append(data)
label = mx.nd.array(np.reshape(label_all, (self.batch_size, self.length)))
mx_label.append(label)
self.q.put(obj=DataBatch(mx_data, mx_label), block=True, timeout=None)
def next(self):
if self.q.empty():
logging.debug("waiting for data......")
if self.cur_batch < self.num_batch:
self.cur_batch += 1
return self.q.get(block=True, timeout=None)
else:
raise StopIteration
def get_network():
dilate = [2**i for i in range(1, 9)]
shape = {}
params = {'length': 2**15, 'batch_size': 100, 'num_batch': 1000}
batch_size = params['batch_size']
length = params['length']
data = mx.symbol.Variable(name="input")
net = causal_layer(data=data, name="causal")
shape = {
"input": (batch_size, 1, 1, length),
"causal-zero": (batch_size, 1, 1, 1)
}
residual = []
outs = []
for d in dilate:
name = "residual-"+str(d)
output_channel = 16
net, out = residual_block(data=net, kernel=(1, 2), dilate=(1, d), num_filter=32, stride=(1, 1), output_channel=output_channel, name=name)
residual.append(net)
outs.append(out)
shape[name+"-zero"] = (batch_size, output_channel, 1, d)
net = outs[0]+outs[1]+outs[2]+outs[3]+outs[4]+outs[5]+outs[6]+outs[7]
net = mx.symbol.Activation(data=net, act_type="relu", name="sum-activation")
net = mx.symbol.Convolution(data=net, kernel=(1, 1), num_filter=128, name="post-conv1")
net = mx.symbol.Activation(data=net, act_type="relu", name="post-activation1")
net = mx.symbol.Convolution(data=net, kernel=(1, 1), num_filter=256, name="post-conv2")
net = mx.symbol.SoftmaxOutput(data=net, name="softmax", multi_output=True)
return net, shape
|