在深度学习中,随着模型和数据的不断增长,在大部分情况下需要使用多卡或者多机进行训练。在多卡或者多机训练中。一般有数据并行和模型并行两种并行方案,数据并行的参数更新中有同步更新和异步更新两种方法,本文讨论的是数据并行中的同步参数更新的一种方法。
模型并行和数据并行
模型并行和数据并行是两种不同的并行方法。
模型并行是网络的不同部分分布在不同的计算节点上,甚至是同一个 Op 也可以分布在不同的计算节点上,所有的计算节点的数据数据是相同的。
数据并行中,每一个计算节点都有一个网络的完整的拷贝,每一个节点使用不同的输入数据,每个节点完成一个完整的 forward 和 backward。
同步更新和异步更新
数据并行中,每个节点完成 forward 和之后和 backward 之后,分别得到了网络的梯度,如何使用这些梯度进行模型参数的更新呢?
同步更新的方法是,等待所有的节点完成 forward 和 backward 之后,把所有节点的梯度收集起来,然后去更新参数,这个过程和原始的 mini batch sgd 是等价的。
异步更新的方法是,每个计算节点完成 forward 和 backward 之后,马上使用自己得到的梯度去更新模型参数,这个过程和原始的 mini batch sgd 是不等价的。例如,考虑两个计算节点的情形,假设两个计算节点跟别是 A 和 B,它们使用 t 时刻的模型参数\(\theta_t\) 去 forward 和 backward 计算。理论上,A 和 B 更新\(\theta_t\) 才和 mini batch sgd 等价。假设 A 计算的比较快,A 计算完之后去更新\(\theta_t\) 得到了\(\theta_{t+1}\)。然后 A 继续使用 \(\theta_{t+1}\) 去 forward backward 计算然后继续更新 \(\theta\)。当计算较慢的 B 节点去更新参数的时候,B 得到的参数是针对\(\theta_{t}\),而此时模型已经变成了\(\theta_{t+1}\),因此,B 有两个选择,要么强制更新\(\theta_{t+1}\),但是,这就和 mini batch sgd 不等价了,要么扔掉 B 的计算结果,不更新参数,这种情况,B 的存在就没有意义了。
PS:异步更新方法也有一些数学上的条件保证异步更新也可以使得模型收敛,比较常用的方法是强制更新的方法下,每隔 n 个迭代,强制同步一次。具体 n 的选择也有数学形式的要求。
本文要讨论的是数据并行中的同步参数更新的一种工程实现。一种常用的方法是 Parameter Server,本文要介绍的是 Ring Allreduce 方法。下面首先简要描述一下 Parameter Server。
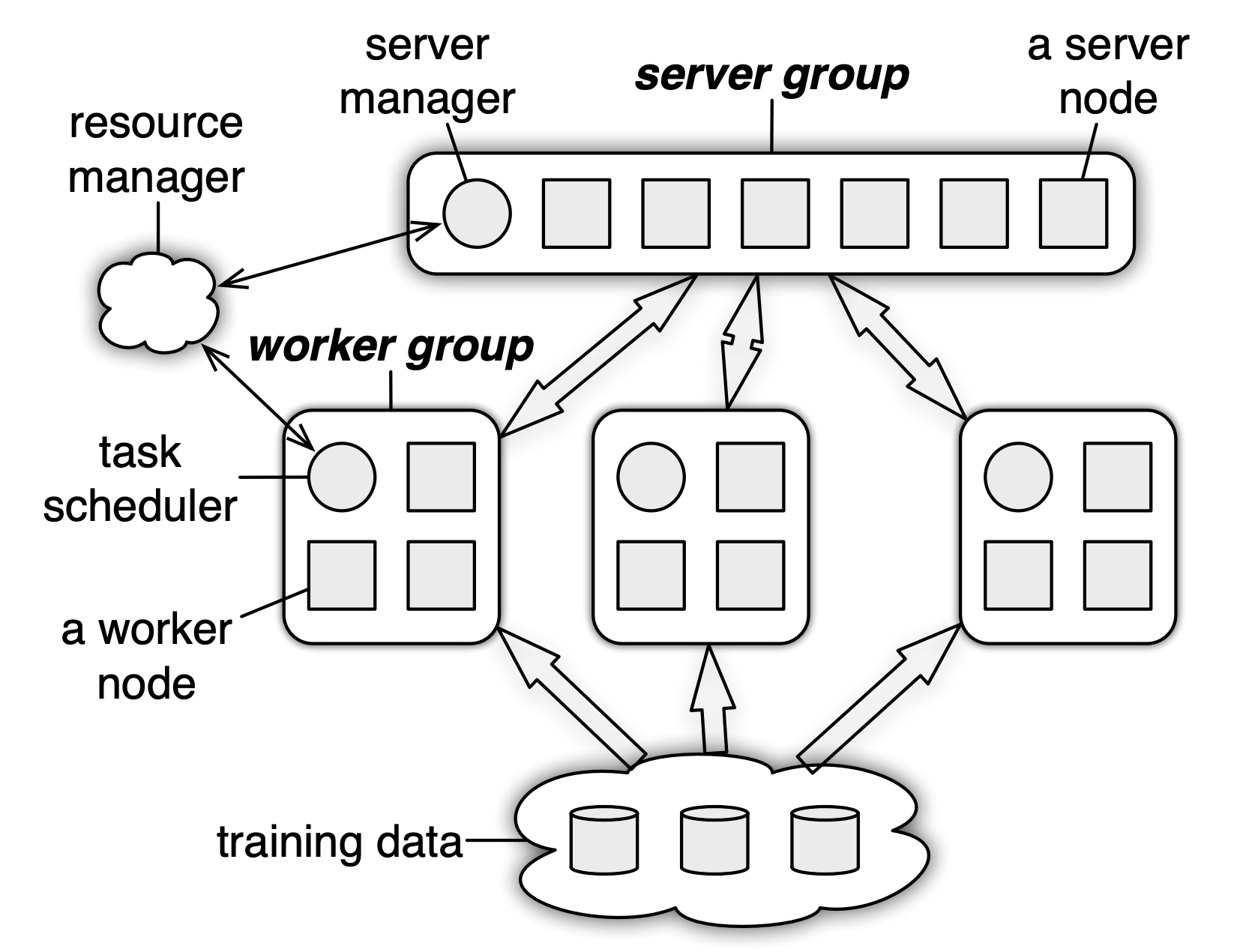
Parameter Server
如下图,PS 中的参数集中在 Server Group 中更新。Worker Group 计算得到梯度之后全部传给 Server Group,Server Group 收集到所有的 Worker 的梯度后更新模型参数\(\theta\),然后 worker 拉取新的参数\(\theta_{t+1}\) 继续进行计算。这里面很容易看到一点,随着集群中的 worker 的数量增多,worker 和 server 之间的通讯会量会线性增长,因此,worker 和 server 之间的带宽成为整个系统的瓶颈。Ring Allreduce 就是为了解决这个通讯瓶颈。
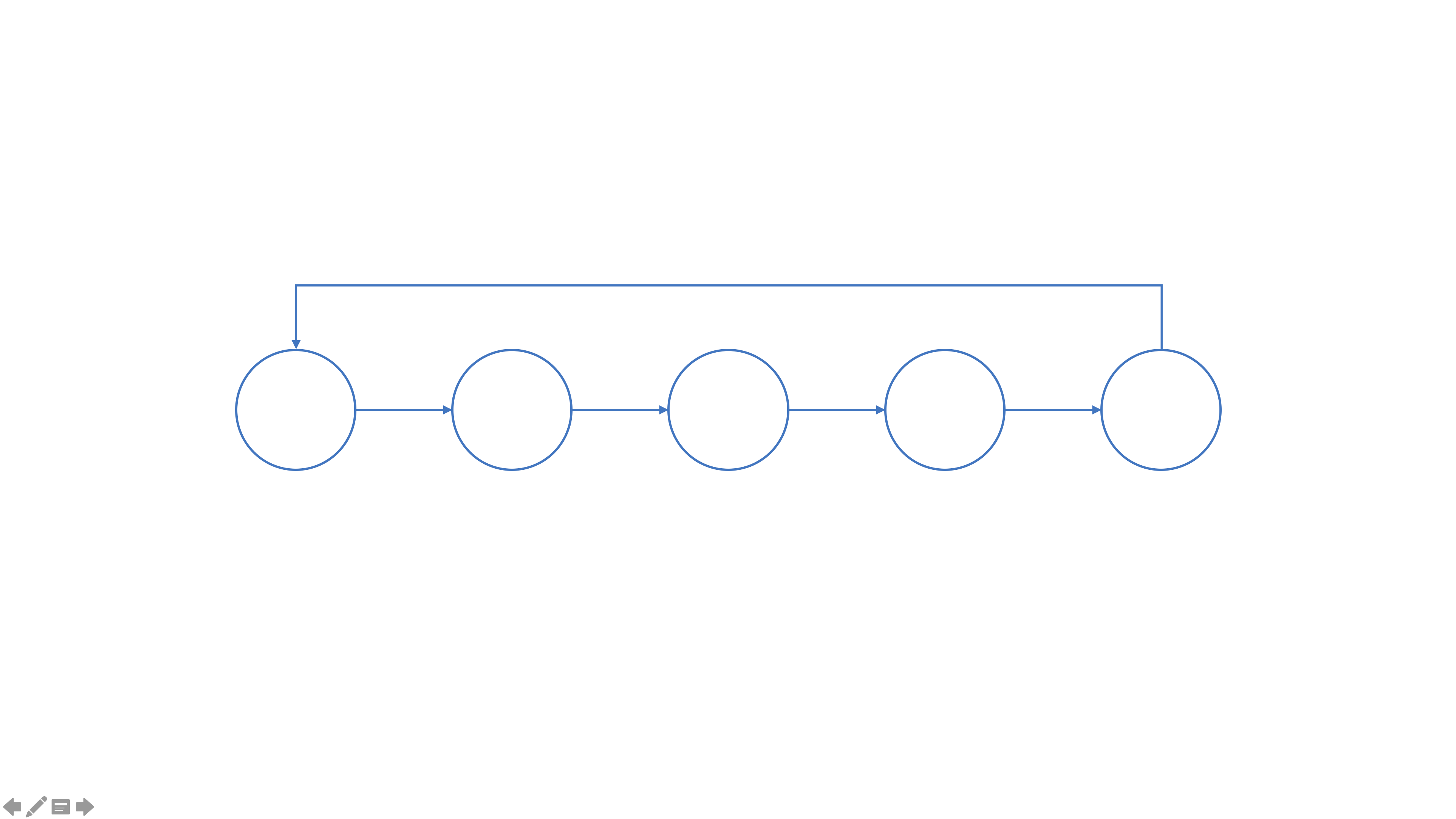
Ring Allreduce
在 ring allreduce 中,所有的节点组成一个逻辑上的圆环,每一个节点都有一个左邻居和一个右邻居,并且,当前节点只能想其右邻居发送数据,只接收来自其左邻居发送的数据。
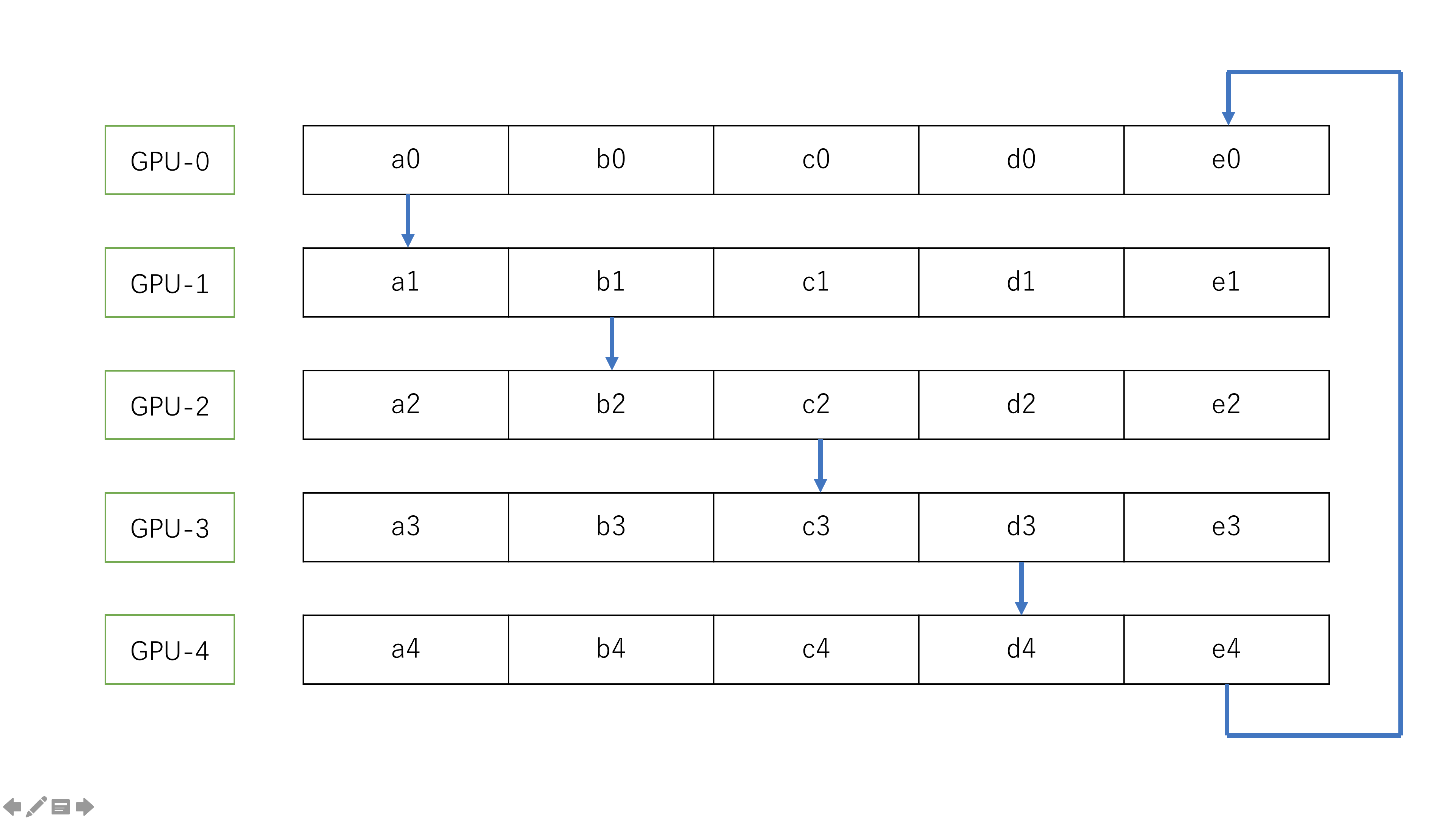
在 ring allreduce 算法中,分为两步执行,第一步是 scatter-reduce,第二部是 all-gather. 在 scatter-reduce 中,每一节点交换数据,交完完成之后,每一个节点获得了所有要交换的数据的一个完整的 chunck,在 all-gather 中,所有的节点交换 chunk 数据,在交完结束之后,每一个节点获得了完整的数据。
scatter-reduce 过程
在数据交换之前,首先把数据分成 N 份接下来,节点之间完成 N 次数据交换,每一次数据交换,系统中的每个节点把自己的一个 chunck 的数据发送给其右邻居,并且接收其做邻居发送来的数据并且做累加。依次如下图:
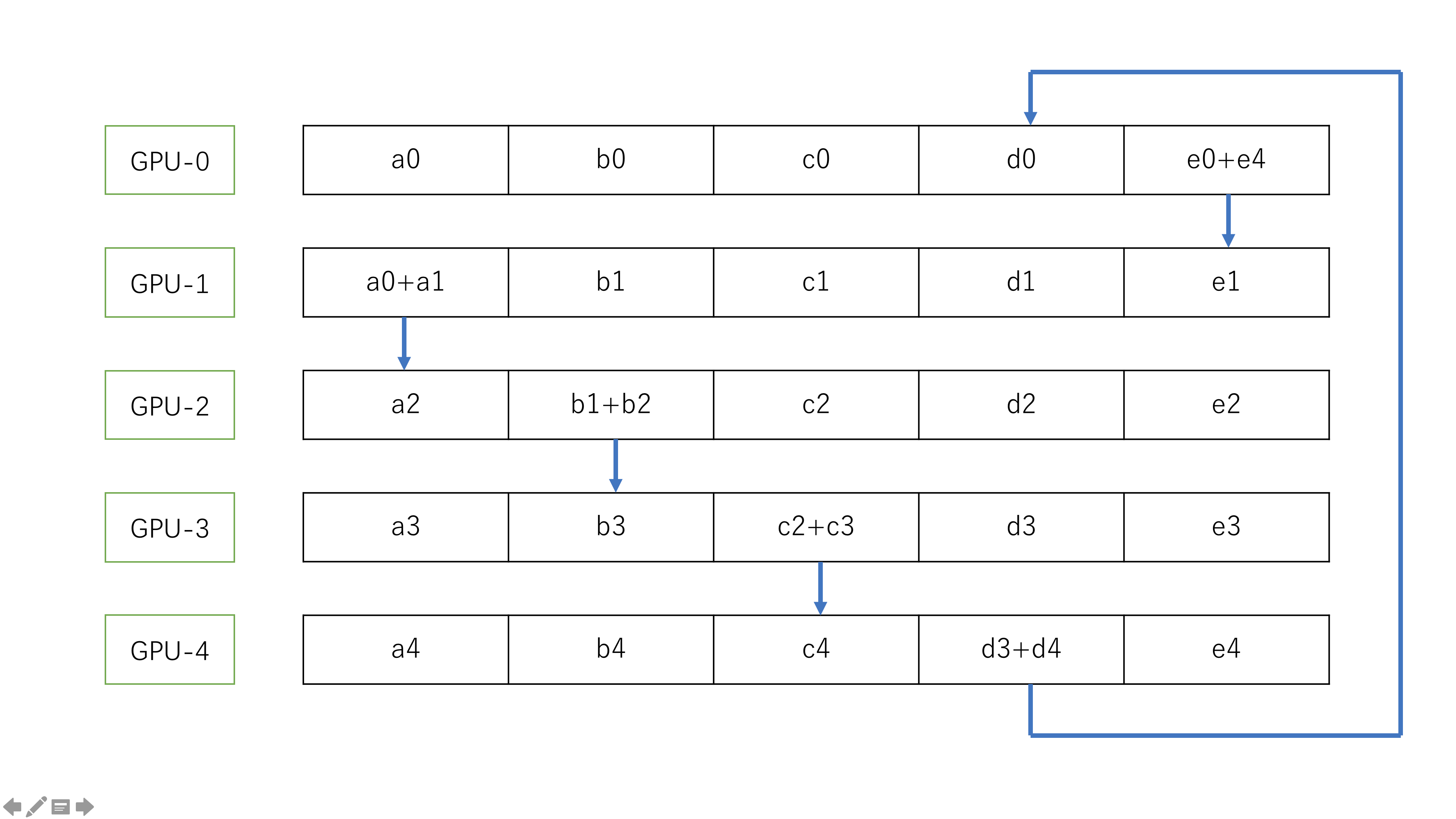
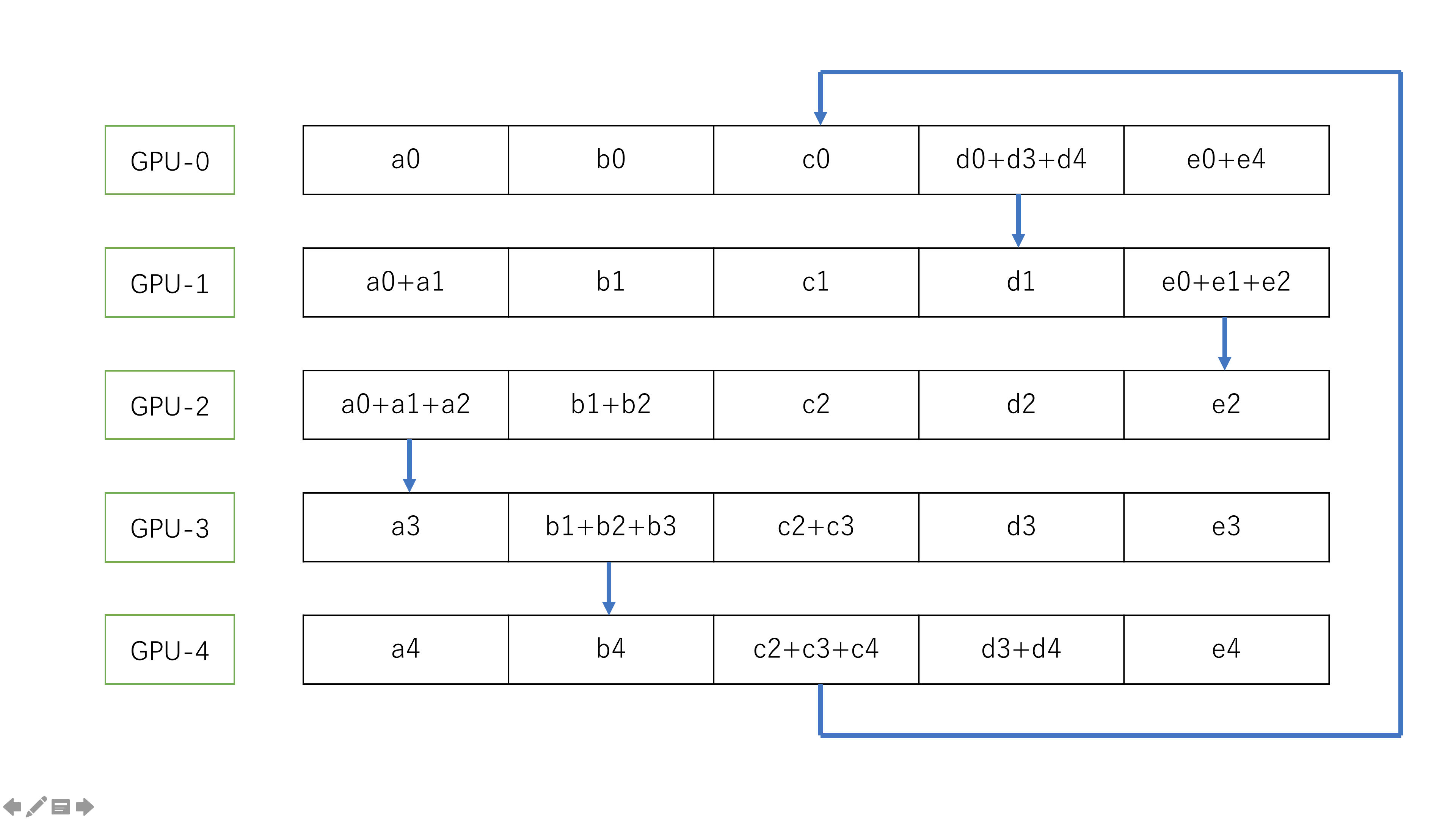
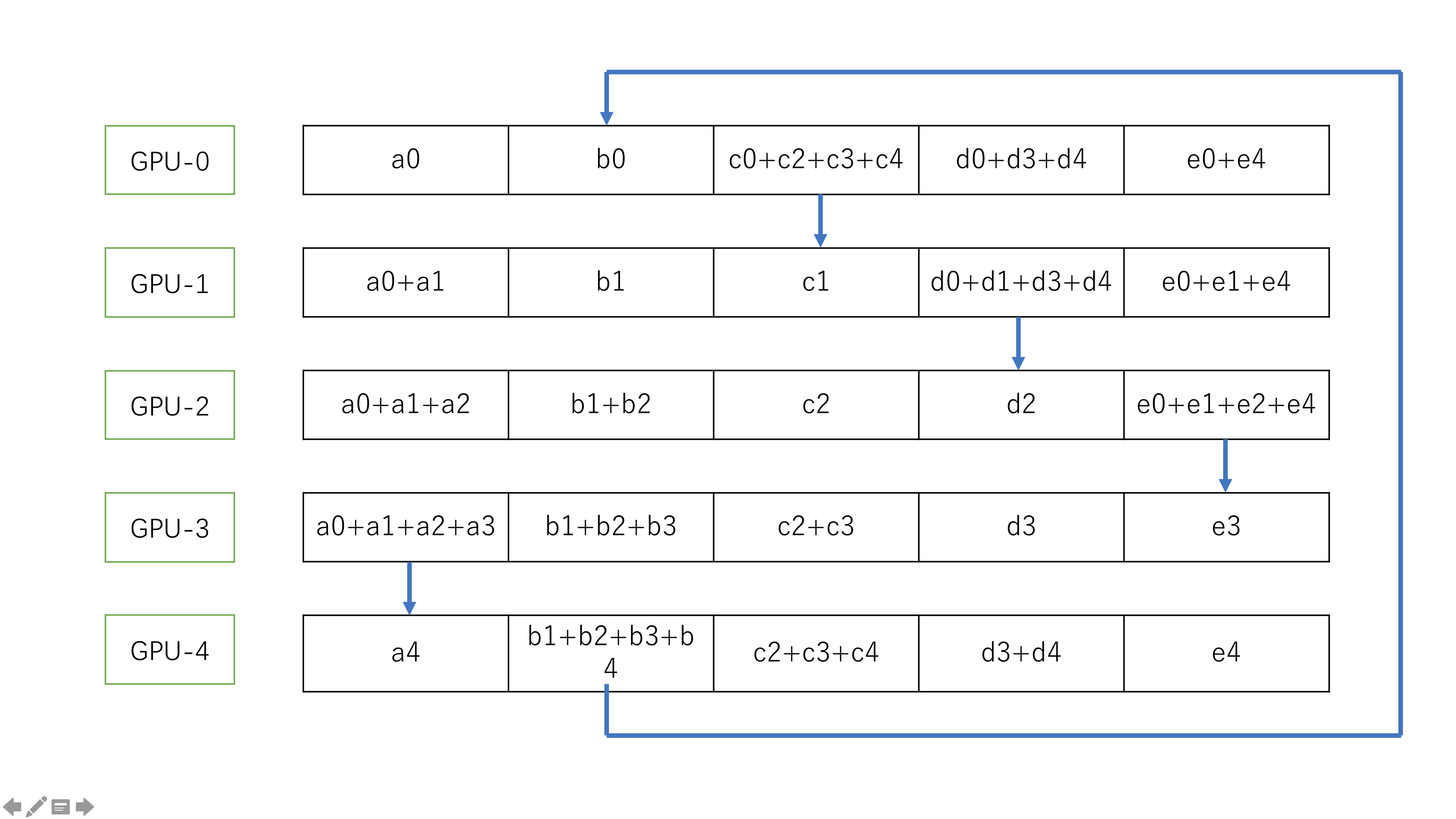
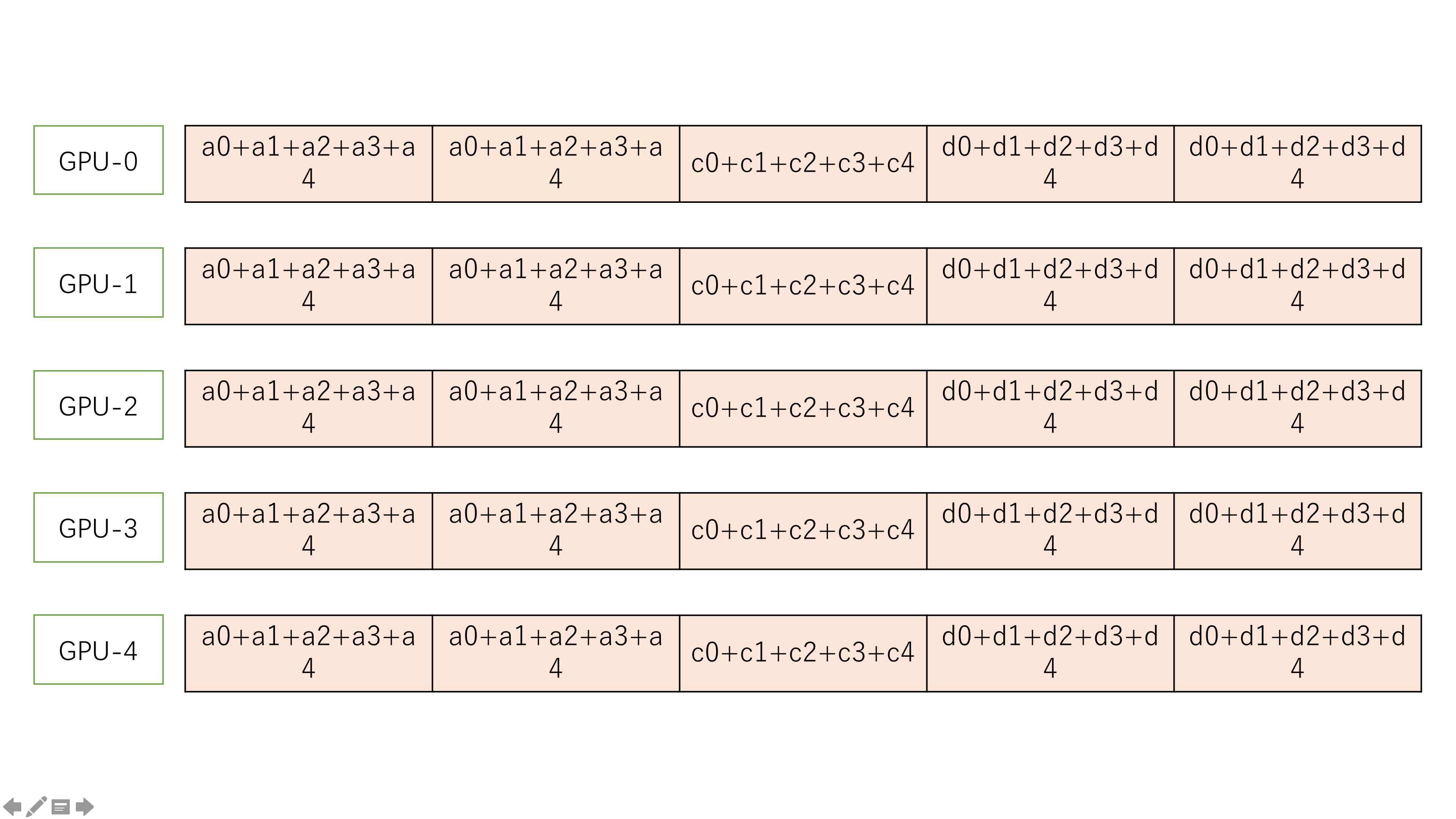
最终,scatter-reduce 过程得到的结果是:

all-gatcher 过程
all-gather 过程和 scatter-reduce 过程类似,唯一的不同是,当前节点接收到其做邻居发送来的数据之后不是做累加,而是用接收到数据覆盖自己的数据。如下图:

最终得到的结果是: