ResNeXt 和 ResNet, GoogleNet 都是首先构建 building block, 然后把多个 building block 串联起来形成最终的网络结果。这种方法的好处是减少了 hyper-parameters, 而且,这种方法得到的模型适应性更好,也就是说不会再 A 数据集上效果很好,换成 B 数据集效果就很差。ResNeXt 沿用了 ResNet 中 shortcut 的思想,但是,ResNeXt 在 building block 上做了很大的改进。针对每一个 building block 在宽度上进行了拓展,输出的 feature map 的 channel 的数量减少,进而,减少了参数的数量。
GoogleNet 中的 Inception 结构证明了通过仔细设计网络的图谱结构,可以在较低的理论复杂度的条件下获得较高的精确度。Inception 的主要策略就是 split-transform-merge. 在 Inception 中,
- 把输入通过 \(1 \times 1\) 的卷积 split 成多个 embeddings,
- 使用特定的卷积核,例如 \(3 \times 3\), \(5 \times 5\) 的卷积核进行 transform 操作,
- 通过 concat 操作把 transform 的结果 merge 起来。可以证明这种结构的解空间是一个单纯的大的层结构在高维嵌入上解空间的子集。
Inception 这种结构在图像识别尤其是 ImageNet 上面取得了非常好的结果,但是,在 GoogleNet 中,每一个 transformation 都要仔细设计,而且,每一个 stage 的这种 module 都不同。ResNeXt 结合了 ResNet 和 Inception 这两种网络的特点,设计了全新的 split-transform-merge 策略。ResNeXt 中每一个 module 都在一个低维的 embedding 上做一系列的 transformation, 然后,把结果 加起来. 其中一个重要特点是所有被 aggregate 的 transformations 的结构都是相同,这样做的结果就是 transformation 的数量可以任意改变而不需要重新设计 transformation 的结构。如下图:
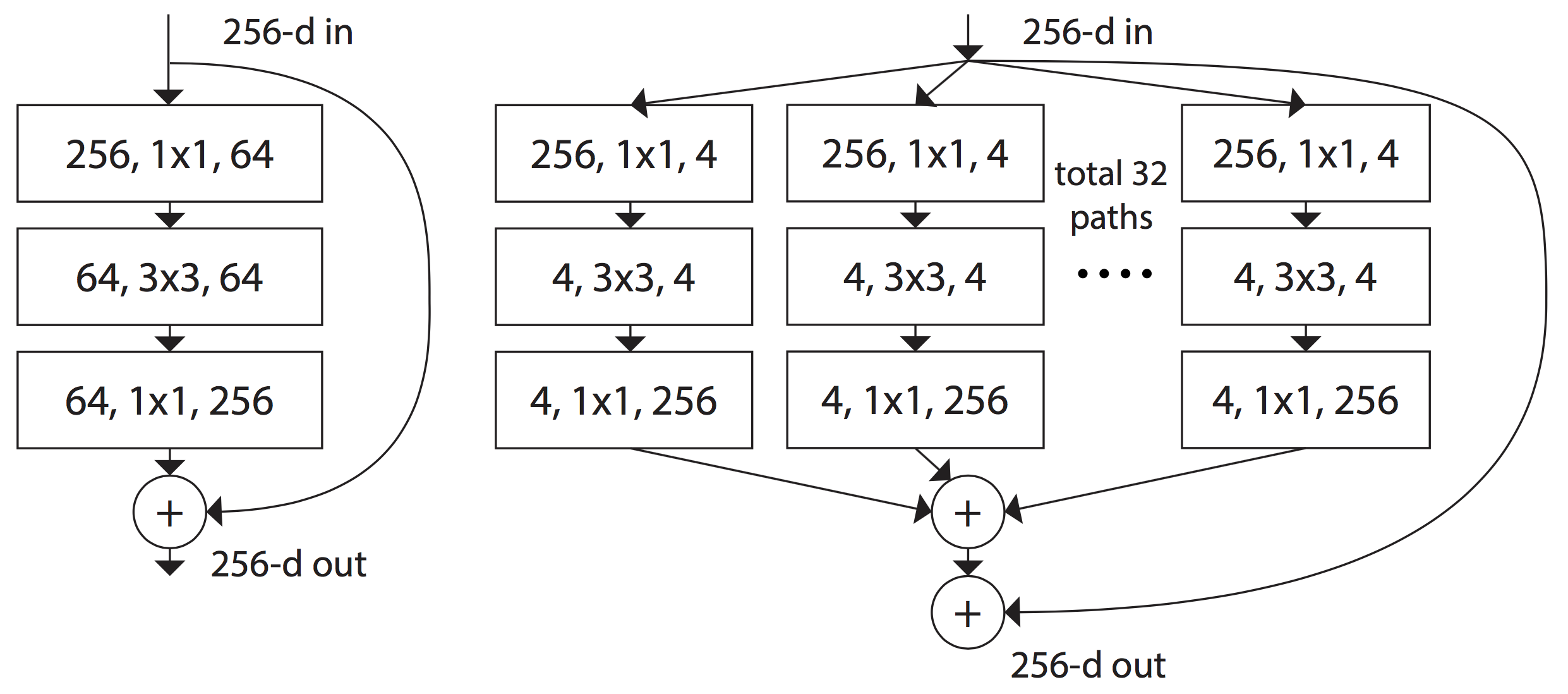
ResNeXt 有两种等价的形式,如下图:

工程上的考虑,实际实现的是第三种。
在保持计算复杂度和模型大小的前提下,ResNeXt 仍然比 ResNet 结果要好,这一点很难得,因为通常情况下,准确率的提升通常伴随着计算复杂度/模型大小的提升。
ResNeXt 证明,cardinality (transformation 集合的大小) 是和网络的深度,网络的宽度一样,都是具体的,度量的一个维度,而且,增大 cardinality 是比增加网络的深度或者宽度更加有效的一种提升网络性能的方法. 101 层的 ResNeXt 比 200 层的 ResNet 准确率要高,而复杂度只有后者的 \(50%\).
ResNeXt 的构建方法很简单,首先设计一个 template, 然后,遵循两个和 ResNet 相似的原则:
- 如果输出相同 size 的 spatial map, 那么,block 的 hyper-parameters (即 width 和 filter size) 相同
- 每次 spatial map 以参数 2 被 downsample 了,那么,block 的 width 就增加到原来的 2 倍.(目的是使所有的 block 的计算量差不多)