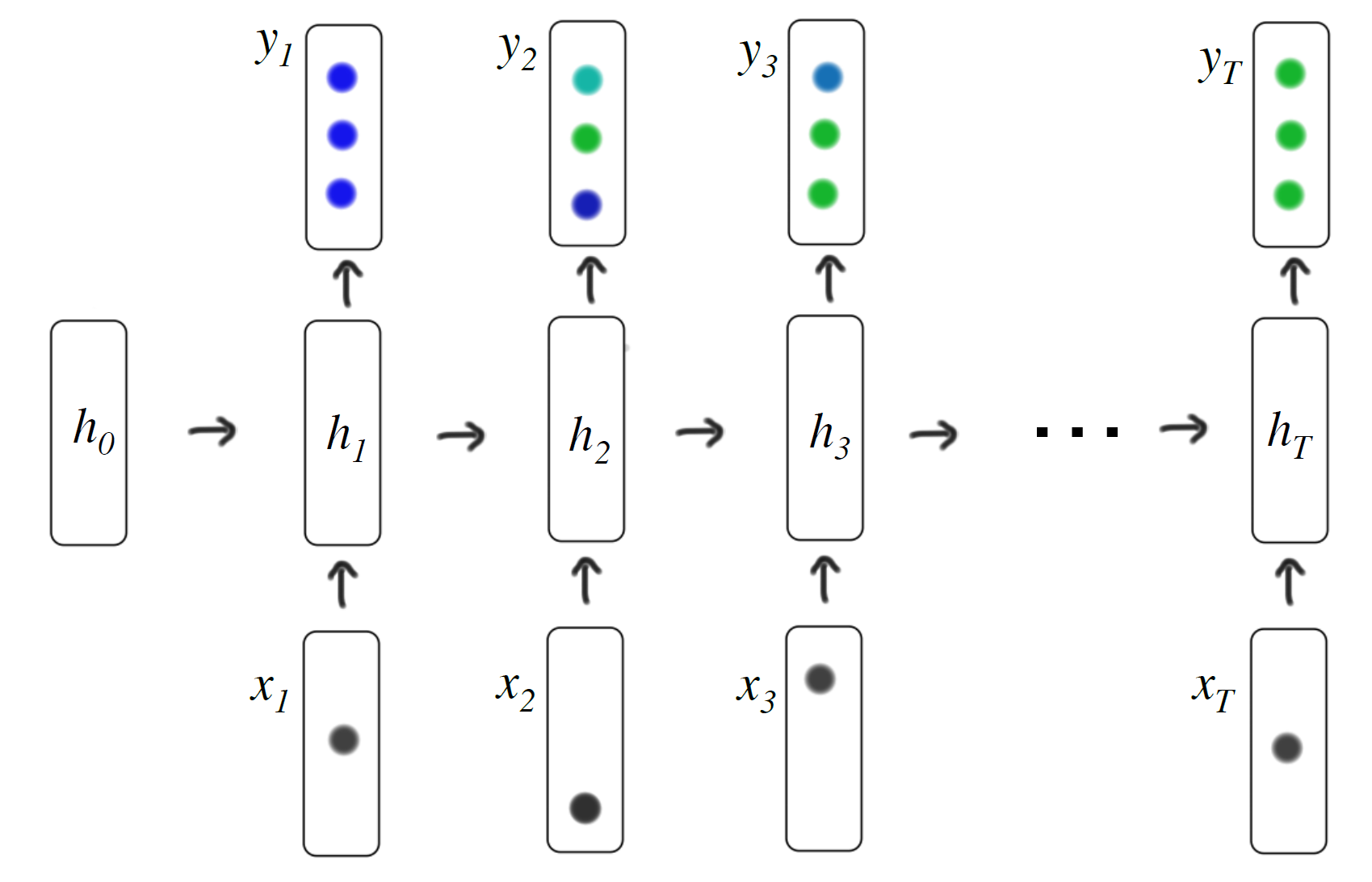
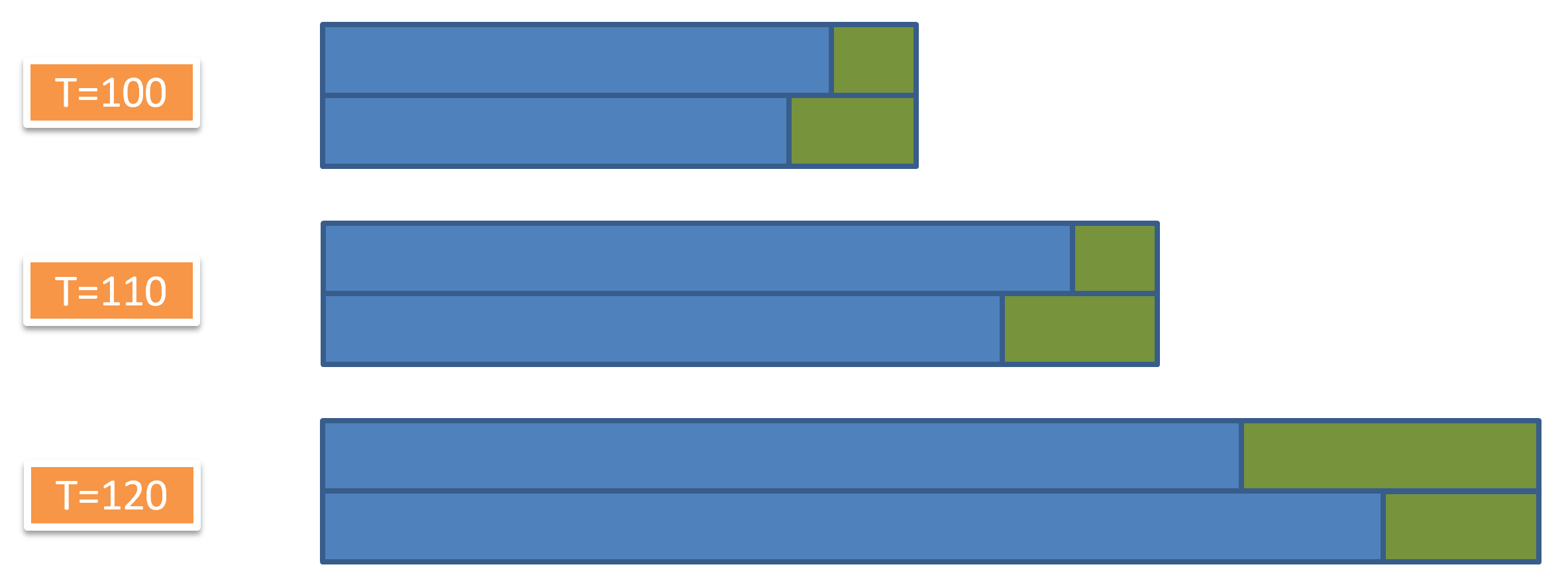
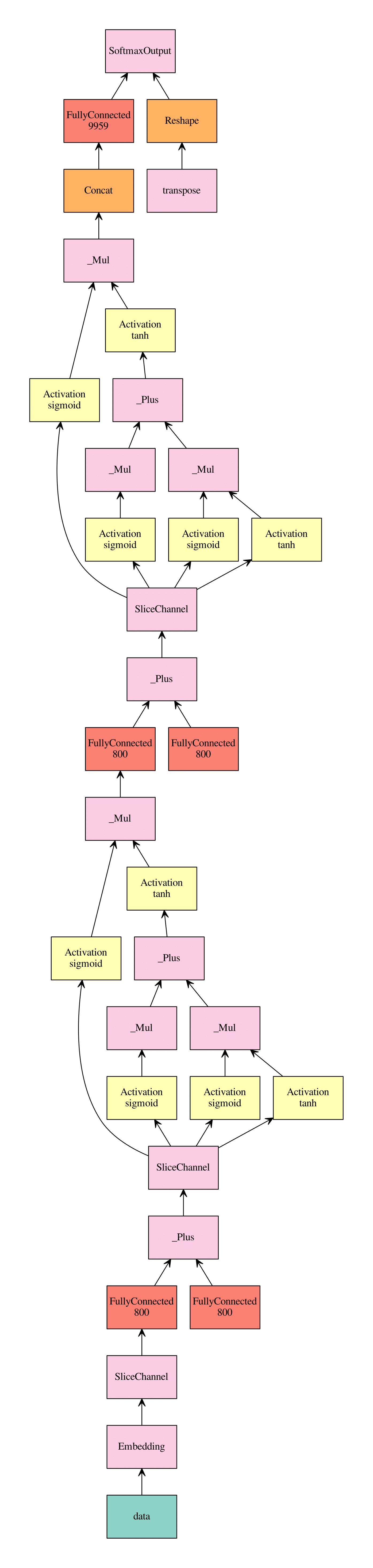
defswitch_bucket(self, bucket_key, data_shapes, label_shapes=None): """Switch to a different bucket. This will change `self.curr_module`. Parameters ---------- bucket_key : str (or any python object) The key of the target bucket. data_shapes : list of (str, tuple) Typically `data_batch.provide_data`. label_shapes : list of (str, tuple) Typically `data_batch.provide_label`. """ assertself.binded, 'call bind before switching bucket' ifnot bucket_key inself._buckets: # 这里体现了 DataIter 中的 bucket 的作用 symbol, data_names, label_names = self._sym_gen(bucket_key) module = Module(symbol, data_names, label_names, logger=self.logger, context=self._context, work_load_list=self._work_load_list) module.layout_mapper = self.layout_mapper module.bind(data_shapes, label_shapes, self._curr_module.for_training, self._curr_module.inputs_need_grad, force_rebind=False, shared_module=self._curr_module) self._buckets[bucket_key] = module # self._buckets 存放的是 bind 了 input shape 的 forward model. 在 forward 的时候只需要把输入 feed 到模型中就可以了。 self._curr_module = self._buckets[bucket_key]
参数共享
这里,首先要理解的一点是,MNXet 根据节点,或者说是 Variable 的 name 去初始化 / 寻找权值参数. 例如,在 transfer learning 中,如果在 pretrain 的模型中找到相同的 name 那么就用 pretrain 的模型中的数值去初始化待训练的 Symbol 的参数,如果找不到,使用默认的方法初始化。这里也是类似的方法。
defbind(self, data_shapes, label_shapes=None, for_training=True, inputs_need_grad=False, force_rebind=False, shared_module=None, grad_req='write'): """Binding for a `BucketingModule` means setting up the buckets and bind the executor for the default bucket key. Executors corresponding to other keys are binded afterwards with `switch_bucket`. Parameters ---------- data_shapes : list of (str, tuple) This should correspond to the symbol for the default bucket. label_shapes : list of (str, tuple) This should correspond to the symbol for the default bucket. for_training : bool Default is `True`. inputs_need_grad : bool Default is `False`. force_rebind : bool Default is `False`. shared_module : BucketingModule Default is `None`. This value is currently not used. grad_req : str, list of str, dict of str to str Requirement for gradient accumulation. Can be 'write', 'add', or 'null' (default to 'write'). Can be specified globally (str) or for each argument (list, dict). """ # in case we already initialized params, keep it ifself.params_initialized: arg_params, aux_params = self.get_params()
# force rebinding is typically used when one want to switch from # training to prediction phase. if force_rebind: self._reset_bind()