LSH (Local Sensitive Hash) 是一种在大规模数据中寻找相似数据的方法。LSH 算是一种随机算法 (Random Algorithm). Random Algorithm 的特点是,它不能保证每次都返回准确的结果,但是,它是已较高的概率保证返回正确的结果,或者是与正确结果很接近的 value. 而且,如果计算资源足够,概率可以 as high as desired. LSH 以小概率的搜索失败为代价,大幅度降低了搜索时间复杂度。
问题描述
给定一个 query point, 需要在数据集中找到该 point, 或者,找到与该 query 最接近的 point. 对于任意一个 query point, 希望算法能够以 \(1-\sigma\) 的概率保证能够找到最相似的 point. 理论上讲,可以通过线性搜索的方法,遍历一遍整个数据集,对于数据中的每一个 point, 计算与 query point 的距离 (例如欧氏距离), 但是,考虑到数据集中的数据达到上千万条,每个数据是成百上千维的向量,因此,线性搜索的方式耗时非常长。因此,在这种情况下,就不能使用线性搜索了。目前场合用的方法是树方法和 Hash.
树方法
树方法和二叉树的搜索很相似:从根节点开始,分别和左子树和右子树的根节点比较,重复该过程。理想的时间复杂度是 \(O(N)\). 如果,是一维空间,就是 binary search, 如果是高维空间,就是 kD tree. KD tree 在空间维数比较高的时候也会 break down, 时间复杂度退化到 \(O(N)\).
Hash
Hash 通过 hash function 把一个 point 映射到一个 value, 通常,point 是高维的,value 是低维的。在 hash 的过程中有可能把不同的 points 映射到了同一个 value, 有很多方法解决这个问题。一个 well designed hash table 可以在 \(O(1)\) 的时间内完成搜索 (吊炸天~). 理想的 hash function 可以把相似的 points 分到不同的 buckets. 这样,通过 hash table 可以在 \(O(1)\) 的时间内找到 the exact match. 然而理想很完美,现实中很难找到这样的 hash function. 于是,就有了 LSH 来找到 approximate (near) matches.
Local Sensitive Hash
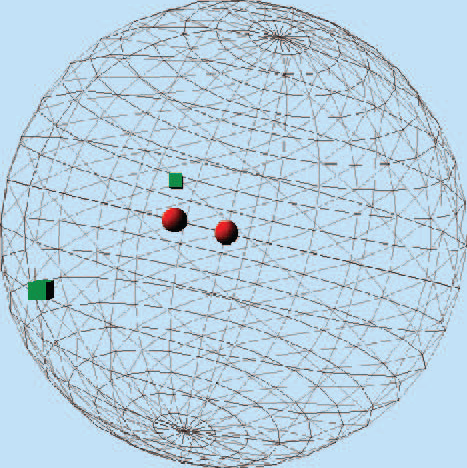
LSH 的想法很简单,如果两个 points 本来就比较接近,那么,在通过 “projection” 之后的位置仍然是接近的。反之,如果距离较远,hash 之后距离仍然较远. 例如,在下图中,在球面上面,两个圆点比较接近,两个方点的距离比较远,那么,把该球面上的所有的点投影到平面上的时候,以较大概率发生的是:两个原点仍然距离较近,两个方点的距离仍然较远.(只有在一些比较特殊的角度上面投影,才会使得投影后的原点距离较远,方点距离较近). LSH 的目的是,如果两个 points 比较相似,那么,通过 hash function 映射之后,这两个 points 落入到 hash table 的同一个 bucket 中,反之,如果不相似的 points 落入到不同的 bucket 中。因此,在 LSH 中,重点是找到符合要求的 hash function.
LSH 所有的魔法全部集中在 LSH hash function 上面。LSH hash function 的要求是:
对于 \({\cal R}^d\) 中的两个相似的点 \(p\) 和 \(q\), 通过 hash 之后,它们有较高的概率落入到同一个 bucket 中。
\[ P_H \left[ h(p)=h(q) \right] \geq P_1 \text{ for } \Vert p-q \Vert \leq R_1 \]对于 \({\cal R}^d\) 中的两个不相似的点 \(p\) 和 \(q\), 通过 hash 之后,它们有较小的概率落入到同一个 bucket 中。
\[ P_H \left[ h(p)=h(q) \right] \leq P_2 \text{ for } \Vert p-q \Vert \geq cR_1 = R_2 \]
上述公式中,\(R_1 < R_2\). 至于该 hash 函数怎么选择,有很多方法,其中有一种方法是 random projection. 其核心是 scalar projection: \(h(\overrightarrow{v})=\overrightarrow{v} \cdot \overrightarrow{x} \), \( \overrightarrow{v} \) 是高维空间的待搜索的点,\( \overrightarrow{x} \) 是其元素从 Gaussian distribution 中采样得到的向量。然后,这个 scalar projection 的结果通过 hash function 映射到 hash bin. hash function 为:
\[ h^{x,b}(\overrightarrow{v})=\left\lfloor \dfrac{\overrightarrow{x} \cdot \overrightarrow{v}+b}{w} \right\rfloor \]LSH function 保证了 \(P_1>P_2\), 为了 magnify the difference between \(P_1\) and \(P_2\), 可以把 \(k\) 个 hash function 进行 concatenate. 这样,\({\left(\dfrac{P_1}{P_2}\right)}^k \gg \dfrac{P_1}{P_2}\), 如果在 \(k\) 个 hash 中,都成功找到 query point, 就可以以更大的自信说找到的 point 就是最 match 的 point. 然而,这样有个缺点是,通过 concatenate 只有,上述情形发生的概率是 \(P_1^k\), 非常小的值。为了解决这个问题,使用 \(L\) 个 independent 的 projection, 然后,从中对 neighbor 采样。
实现
总的来说,是使用了两个 hash function, \(T_1\) 和 \(T_2\), \(T_1\) 就是用来做传统的 hash.
\[ T_1 = \left( \sum_i H_i k_i \text{ mod } P_1 \right) \]由于在 hash 中存在冲突的现象,所以,LSH 中引入了第二个 hash function \(T_2\), 和 \(T_1\) 形式是一样的,作用是 check that points retrieved from the hash table do indeed match the query. 具体做法是:把 \(T_2\) 的结果 (fingerprints) 存储到 \(I_1\) 对应的 bin 中。于是,在 retrieval 的时候,直接比较 fingerprints, 由于 fingerprints 比较短,速度比直接比较两个 \(k\) 维的向量速度要快。