CNN 基础之 Dropout
Dropout 是一种非常非常通用的解决深层神经网络中 overfitting 问题的方法,过程极其简单,在调试算法中效果也非常有效,几乎是在设计网络过程中必用的技巧。
概述
深层神经网络的参数非常非常多,一般情况下设计的神经网络非常容易 overfitting, 在 CNN 中,Pooling 层具有一定的防止 overfitting 的作用,但是,CNN 的结构一般是多个 conv factory 之后需要使用 full connect 来做分类等任务,由于在 full connect layer 中参数密度比较高,非常容易 overfitting, 而 Dropout 可以用来解决这里的 overfitting 问题 [^1].
具体过程
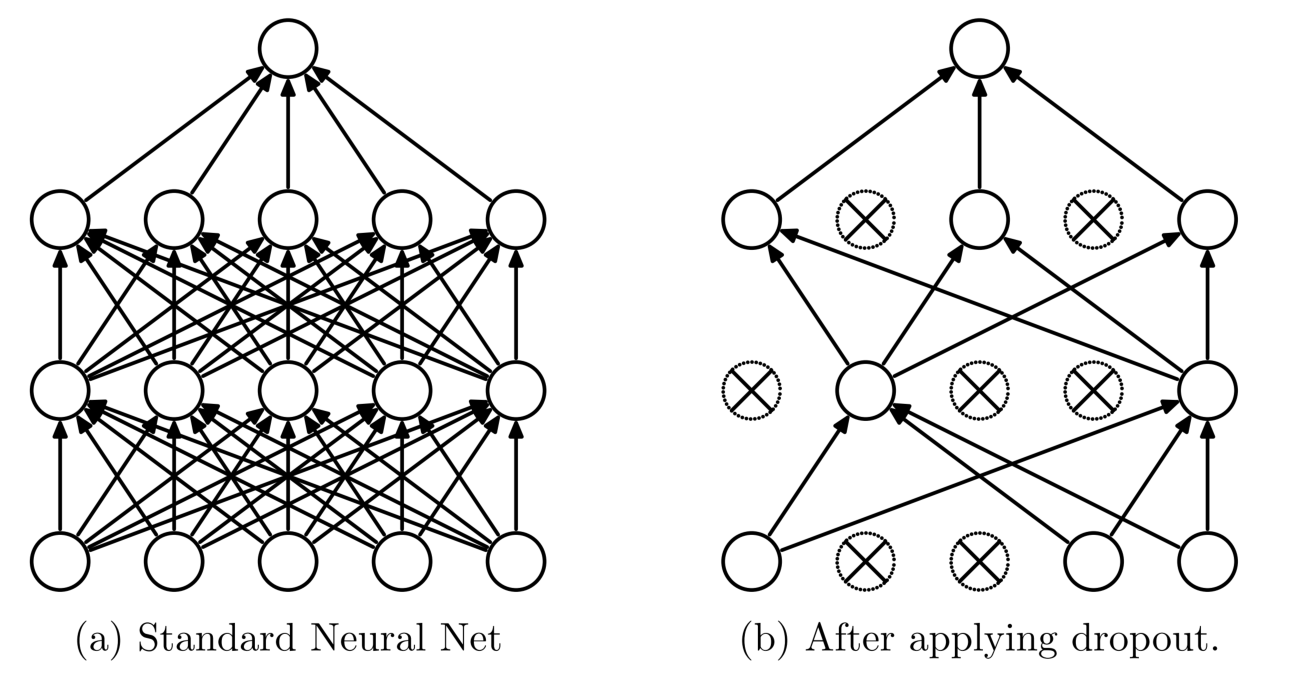
如上图,左边是我们常见的 full connect layer, 右边是使用了 dropout 之后的效果。其操作方法是,首先设定一个 dropout ratio \(\sigma\), \(\sigma\) 是超参数,范围设置为 \(\left (0,1\right)\), 表示在 Forward 阶段需要随机断开的连接的比例。每次 Forward 的时候都要随机的断开该比例的连接,只更新剩下的 weight. 最后,在 test/predict 的时候,使用全部的连接,不过,这些 weights 全部都需要乘上 \(1-\sigma\). 不过,在具体的实现中略有不同,参下面的源码解释。
Side Effect
Dropout 除了具有防止 overfitting 的作用之外,还有 model ensemble 的作用。
我们考虑,假设 \(\sigma = 0.5\), 如果 Forward 的次数足够多 (例如无穷次), 每次都有一半的连接被咔嚓掉,在整个训练过程中,被咔嚓掉的连接的组合是 \(2^n\), 那么,留下的连接的组合种类也是 \(2^n\), 所以,这就相当于我们训练了 \(2^n\) 个模型,然后 ensemble 起来。
MXNet 源码
1 | template<typename xpu> |
CAFFE 源码
1 | void DropoutLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, |
使用方法
MXNet
1 | import mxnet as mx |
CAFFE
1 | layer { |
[^1]: 最近也有一些网络不使用 Dropout, 例如:Network in Network 使用的是 global average pooling 来 handle 的 overfitting 问题,以及 Kaiming 的 Residual Network 也没有使用 dropout, Residual Net 甚至没有使用 Pooling, 而是用 convolution 操作来搞定的降维问题。