深度学习中的依赖引擎
深度学习中,我们希望框架运行速度越快越好,支持的数据集 / 模型越大越好。一种显而易见的方法就是堆机器,堆显卡。这种方案带来的问题是:如何在多台机器,多块显卡上进行并行计算,以及如何在多线程的情况下正确而高效的实现计算的同步。
对于这个问题,通常使用运行时依赖引擎来解决。这篇文章的目的是讨论在深度学习中运行时依赖引擎的调度问题以及怎样通过运行时依赖引擎来加速和简化多设备上的深度学习。本文还探讨了不具体操作的通用依赖引擎的设计方法。
本文中的大部分方法提现在了 MXNet 的依赖引擎中,依赖关系跟踪方法主要由 Yutian Li 和 Mingjie Wang 完成。
Dependency Scheduling
尽管我们都想充分利用并行计算的优势,但是,在实践中,对串行编程更熟悉。因此,能不能通过串行的方式编程,却可以通过异步方式实现具体计算的并行呢?
例如下面的代码,B=A+1 和 C=A+2 可以以任意的顺序或者直接并行地执行。
1 | A = 2 |
但是,直接通过手写代码来确定他们的顺序比较困难,因为上述最后一个操作 D=B*C 需要等到前面两个操作都完成之后才能运行,下面的依赖图 / 数据流图说明了这个问题。
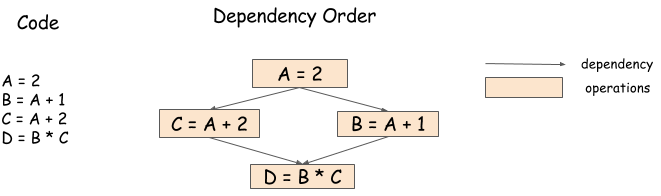
依赖引擎的作用是维护一个操作序列,根据依赖模式进行合理的调度操作序列,从而尽可能地实现操作的并行。因此,在上面这个例子中,B=A+1 和 C=A+2 是并行地运行的,D=B*C 前面两个操作完成之后才运行。
Problems in Dependency Scheduling
依赖引擎使得写并发程序变得很简单,但是,因为操作变成了并行的模式,因此,带来了新的依赖关系跟踪问题。下面分别阐述这些问题
Data Flow Dependency
数据流依赖描述的是一个计算的输出会以什么样的方式被其它的计算使用。任何一个依赖引擎都要解决数据流依赖的问题。
带有数据流跟踪的库包括 Minerva 和 Purine2.
Memory Recycling
给变量分配的内存什么时候回收呢?串行程序比较简单,直接在变量 out of scope 的时候回收。但是,对于并行处理来说,内存回收就变得比较复杂了,如下图:
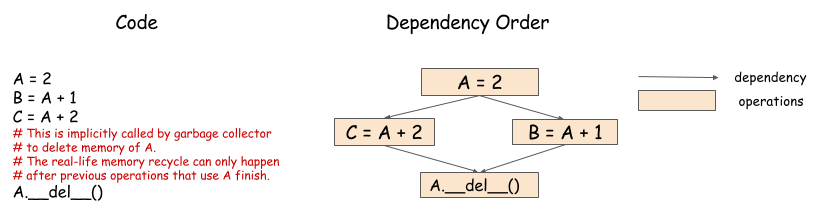
在这个例子中,两个操作都需要依赖于 A, 只有到这两个操作都完成之后才能回收 A 的内存。引擎需要根据依赖关系去回收内存,确保在 B=A+1 和 C=A+2 都完成之后才回收 A 的内存。
Random Number Generation
随机数生成器在机器学习中使用非常普遍,并且给依赖引擎带来新的挑战。例如下面这个例子:
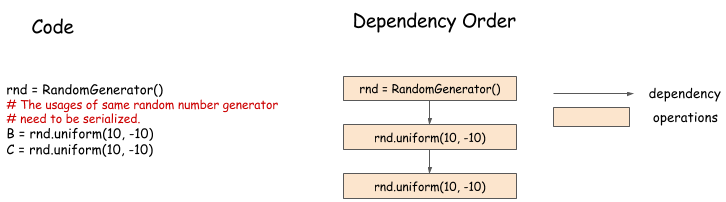
这个例子中,使用的是串行的方式生成的随机数,虽然看上去随机数的生成可以使用并行的方式进行,但是,事实上,伪随机数生成器在生成随机数的过程中会改变内部的状态,因此,伪随机数的生成并不是安全的,这也就导致了随机数的生成不能并行。另外,即使伪随机数生成是线程安全的,我们也不采用并行,因为,通过串行的方式,才能保证随机数的生成结果是可复现的。所以,伪随机数生成需要串行。
Case Study: A Dependency Engine for a Multi-GPU Neural Network
这部分讨论在设计依赖引擎将会遇到的问题。在讨论如何设计一个通用的依赖引擎之前,我们首先来讨论一下,在深度学习中,依赖引擎在多 GPU 的训练中的作用是什么。下面的伪代码描述了一个 batch 的数据是如何在一个两层的神经网络上进行训练的。
1 | # Example of one iteration Two GPU neural Net |
在这个例子中,数据 0 到 40 在 GPU0 上,数据 5 到 99 在 GPU1 上,梯度数据在 CPU 上进行聚合操作,然后,使用 SGD 算法更行模型参数,并且把更新后的参数拷贝到两块 GPU 上。这就是使用串行的方式去写并行程序的一种方式。下面的依赖图描述了并行的过程:
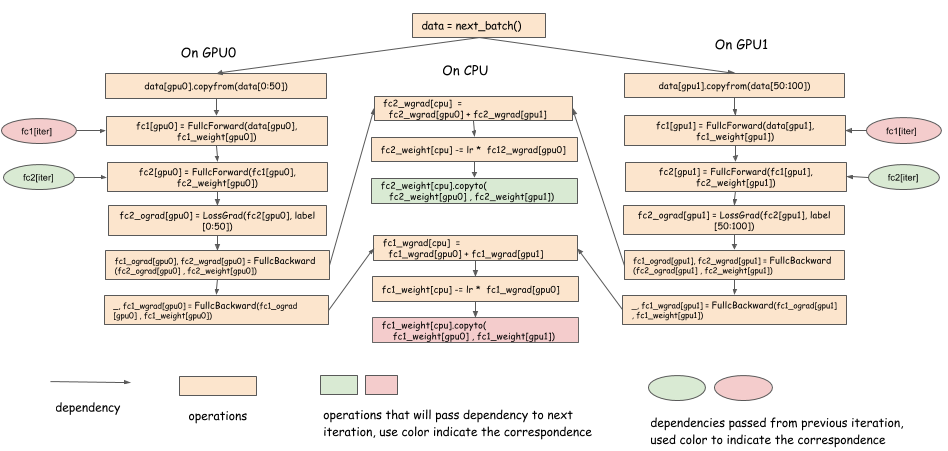
注意:
- 对于每一层来说,一旦计算完得到梯度数据,该梯度数据可以马上拷贝到 CPU 上。
- 模型参数 (权值) 数据在更新完之后可以马上从 CPU 拷贝到 GPU 上
- 在前向传播过程中,需要等待前一个迭代中
fc1_weight[cpu].copyto(fc1_weight[gpu0] , fc1_weight[gpu1])完成之后才能进行。 - 对于第 k 层,在 backward 完成之后,新一轮的 forward 没有开始之前有一个时间差,在这个时间内,我们可以完成数据的拷贝工作 (与其它层的 forward 和 backward 并行地进行).
这种优化方法在多 GPU 的深度学习库中经常被采用,例如 CXXNet. 其关键点是把数据的拷贝和其它的计算进行 overlap. 实现这一点并不容易。因为,在 backward 完成之后要马上进行拷贝操作,接着还要在适当的时候进行 reduction 操作以及参数的更新操作。
Designing a Generic Dependency Engine
至此希望各位对依赖引擎的重要性有了初步的认识。接下来讨论以下如何设计和实现依赖引擎的通用接口。接下来讨论的设计并不是唯一的方案,只是针对大部分情况我们认为是可行的方案。
本文的目标是实现一个轻量的,可通用的依赖引擎。我们希望,这个依赖引擎可以像插件一样很容易的集成到现有的深度学习库中,而且,通过很小的改动就可以应用到多台机器的场景。为了实现这一点,只需要关注依赖的跟踪,而并不需要事先假设用户用户可以进行什么操作或者不可以进行什么操作。
总结来说,本文设计的依赖引擎有以下几个特点 (目标):
对于调度的具体的用户操作是无感知的,这样,用户就可以随便使用任何操作
- 不能只调度某些固定种类的对象
- 即能调度 CPU 上的依赖,也能调度 GPU 上的依赖
- 能够跟踪随机数生成器的依赖等
- 不需要分配资源。要做的仅仅是跟踪依赖。用户自己分配资源,例如内存,伪随机数生成器等。
下面的 Python 代码提供了帮主我们完成目标的引擎接口。当然,实践中的实现是用 C++ 完成的。
1 | class DepEngine(object): |
因为不能对要调度的内容做任何假设,因此,我们要求用户分配一个 virtual tag, virtual tag 是和具体的对象关联起来的,在依赖引擎中,使用 virtual tag 来表示需要调度的内容。因此,首先,用户需要对要调度的内容分配 virtual tag, 并且把调度内容和 virtual tag 做好关联。
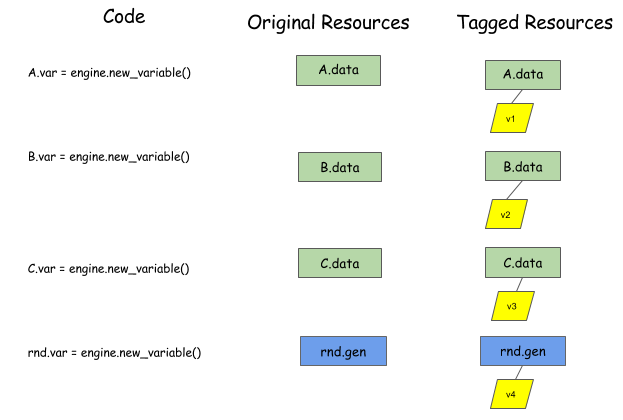
然后,用户调用 push 来告诉引擎需要进行什么操作,并且还要通过 read_vars 和 write_vars 来声明该操作所需的依赖。
read_vars是对象的 tag, push 给引擎的操作只会从该对象中做读取操作,不会改变该对象。write_vars是对象的 tag, push 给引擎的操作将会改变该对象的内容。
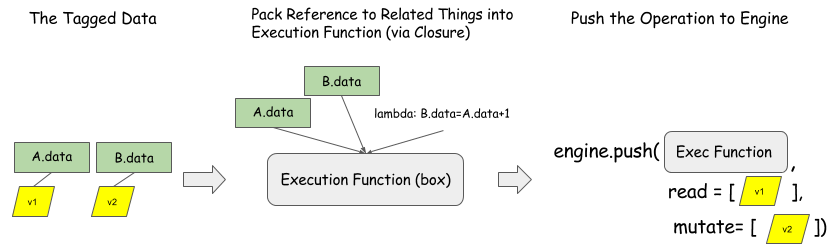
上图描述了把 B=A+1 push 给依赖引擎的过程。B.data 和 A.data 是真正的分配了资源的对象,而引擎拿到的只是对象的 tag. 任何可执行的函数都可以处理。这种接口形式对于操作和资源都是通用。
下面,我们看一下引擎内部是怎样通过 tag 来工作的。考虑下面这段操作:
1 | B=A+1 |
第一行读取的是可变变量 B 和变量 A, 第二行读取可变变量 C 和 变量 A……
引擎对于每一个变量维护了一个队列,过程如下图所示,绿色块表示读取操作,红色块表示写入 (mutation) 操作。

通过队列,引擎发现,A 起始的两个绿色的块是可以并行的,因为,都是读操作,而且,两个操作之间没有任何冲突。如下图所示:
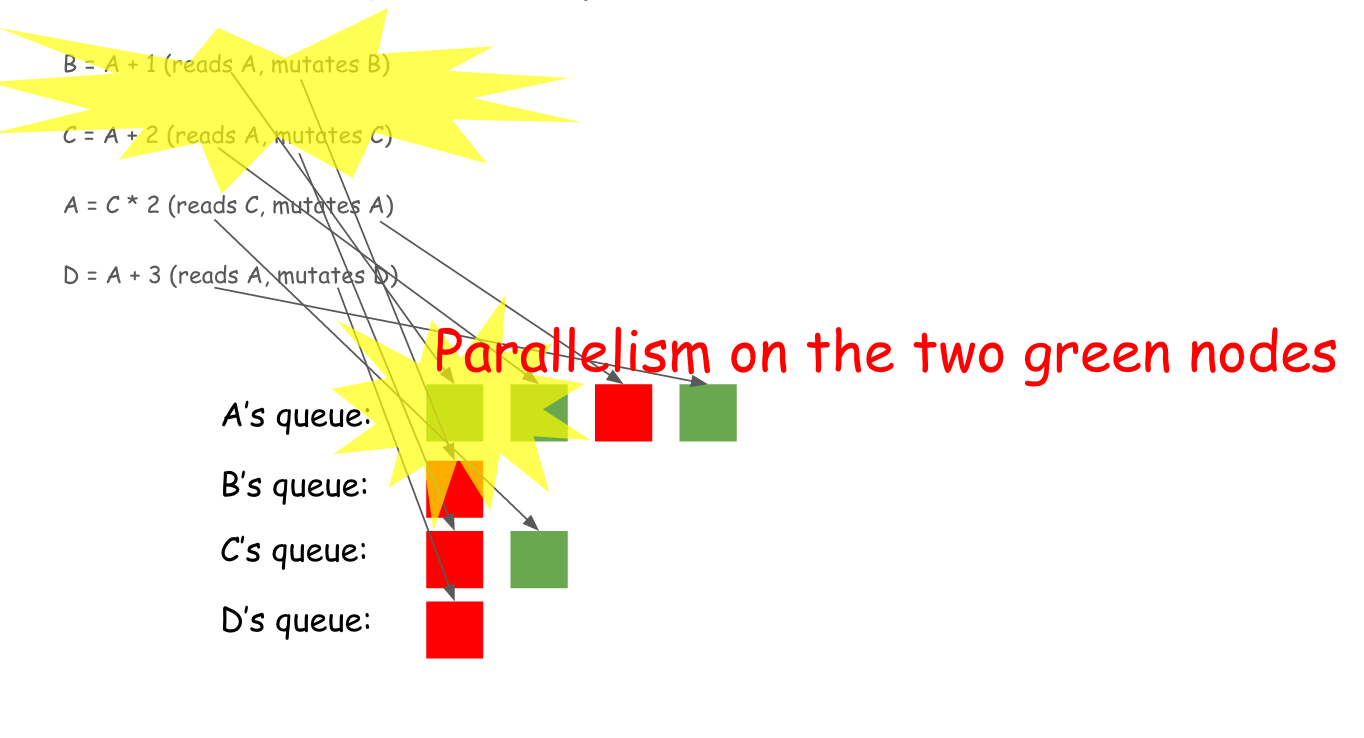
这个引擎最大的特点是,其调度的内容不仅仅限于数值计算,因为,它调度的只是对象的 tag, 因此,可以说,该引擎可以调度任何需要调度的内容。
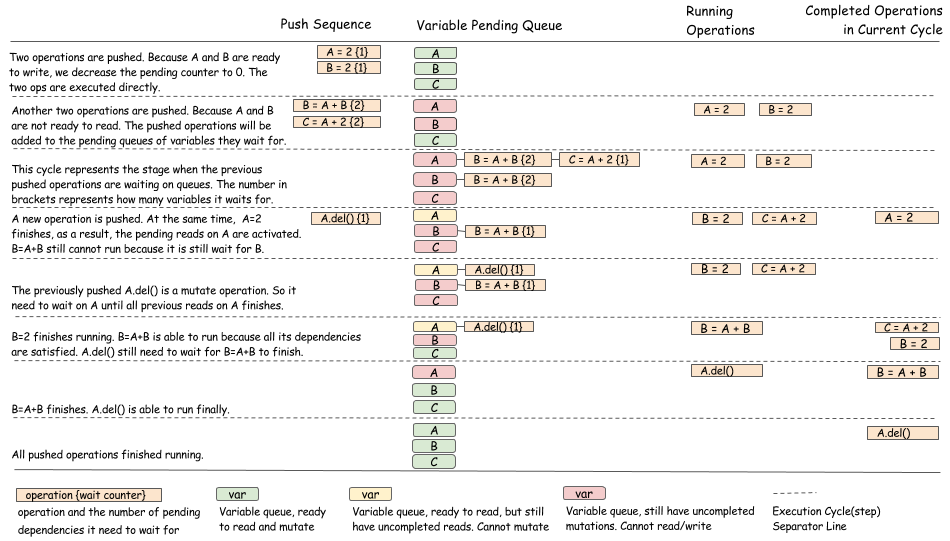
下面这张表描述了前面的程序 push sequence.

Porting Existing Code to the Dependency Engine
该引擎不处理内存分配或者需要运行的操作,因此,大部分现存代码可以很容易地通过本文描述的依赖引擎进行调度,只需要两个步骤:
- 对于所有的资源,例如内存,伪随机数生成器分配 tags
- 通过 push 接口来 push 要进行的操作,并且注意正确地设置
read_vars和write_varstags
Implementing the Generic Dependency Engine
以上讨论了通用调度接口和调度方式,这一部分讨论一下具体的实现。基本内容如下:
- 对于每一个 tag, 使用队列去跟踪目前有多少操作是依赖于该 tag 的
- 对于每一个 operation. 使用 counter 去跟踪还有多少各依赖没有被满足
- 操作完成之后,更新队列 和 counter, 调度新的 operation
下图是调度算法的可视化过程:
下图展示的是带有随机数生成器的例子:
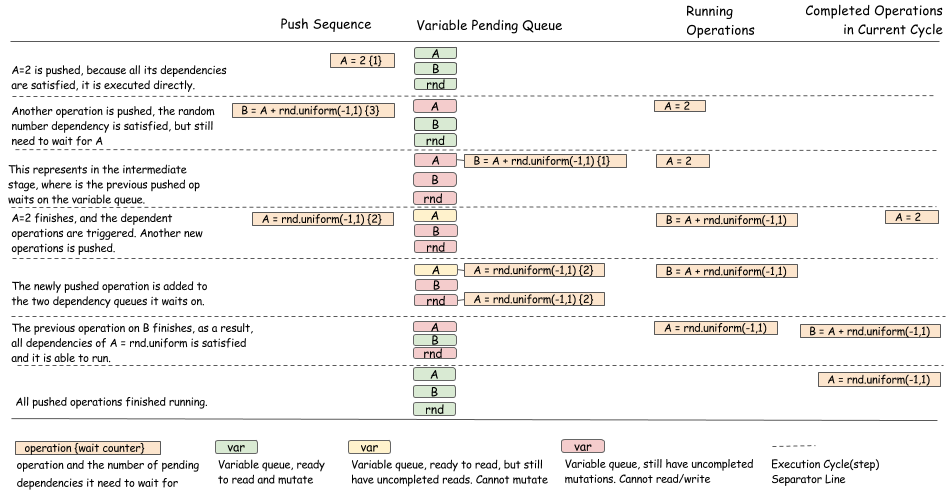
从上面的两个例子可以看出,该算法主要是更新 operation 的等待队列并且在操作完成之后正确的进行状态转换。另外,还要保证状态转换是线程安全的。
Separate Dependency Tracking with Running Policy
以上讨论只是描述了依赖引擎如何决定让一个操作什么时间开始运行的,并没有说明操作是如何运行的。在实践中,有很多方式运行具体的操作。例如,使用全局的线程池来运行所有的操作或者在每一个设备上使用特定的线程运行对应的操作。
操作运行的策略和依赖关系跟踪是完全独立的,操作运行可以分离成一个独立的模块或者依赖关系跟踪模块的虚拟接口。开发一个对所有的操作都公平的运行时策略并且顺利的进行调度这件事本身就是一个重要的系统化问题。
Discussion
这篇文章讨论的设计并不是解决依赖关系跟踪问题的唯一方案。这部分讨论一些其它的方案。
Dynamic vs. Static
本文中讨论的依赖引擎接口在某种程度上是动态的,用户可以逐个推送操作,而不是声明整个依赖关系图 (静态的). 在数据结构方面,动态调度可能需要比静态声明需要更多的开销。然而,动态调度更灵活,例如支持命令式程序的自动并行已经命令式和符号式程序的混合编程。还可以向接口添加一些级别的预先声明的操作,以启用数据结构重用。
Mutation vs. Immutable
本设计中的通用引擎接口支持对可变内容的显示调度。在典型的数据流引擎中,数据通常是不可变的。不可变数据有很多优点,例如,他们通常更容易实现并行化,并且,通过重新计算,在分布式系统中可以更容易的处理容错问题。然而,不可以数据有以下几个问题:
- 很难调度资源竞争问题,例如随机数和删除操作
- 引擎通常需要管理资源(内存,随机数),以避免冲突。很难插入用户分配的空间等。
- 与分配的静态内存不可用,也是通常要写入预分配的空间,但是,如果数据不可便,这个操作无法完成。
数据可变使得上述问题比较容易处理。它在一个比数据流引擎低的级别,在某种意义上,如果我们为每个操作分配一个新的变量和内存,它可以用于调度不可变操作。它也使得事情像随机数生成更容易,因为操作确实是一个状态的变化。