Gluon 是 MXNet 实现的一套同时可以支持动态图和静态图的计算接口。和原有的 Symbol 接口相比,Gluon 的封装层次更高,在某种程度上使用更灵活。本文记录在学习 Gluon 的过程中实现 DeepLab V3 的过程。同时,数据的处理和输入也是使用的 Gluon 中提供的 Dataset 接口。
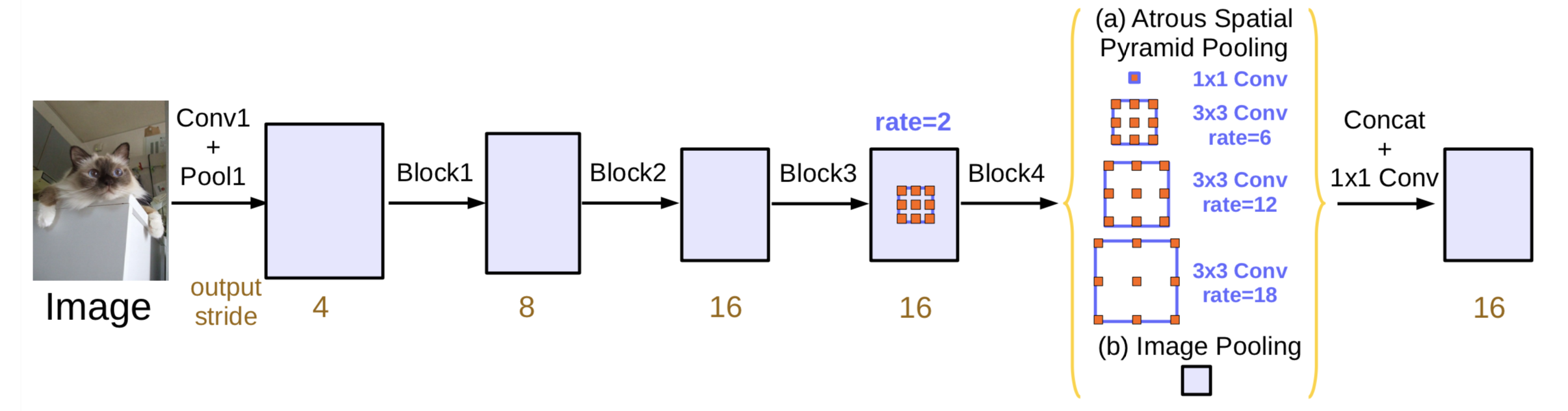
DeepLabV3 首先要简要说明一下 DeepLab V3。DeepLab V3 和 PSPNet 基本一致,主要不同在于如何融合不同特征,改进了 PSPnet 的 ASPP module。PSPNet 在把 dilated conv 作用到 feature map 上的时候,如果 dilation rate 太大,那么,3x3 的 conv 就无法获取全局的特征而是退化到了一个 1x1 的 conv,为了有效提取全局特征,DeepLab V3 使用了 Global average pooling 操作。其它部分基本上和 PSPNet 是相同的,也讲不出什么道理。
Bottleneck 因为基本网络结构延续 resent 的思想,因此,首先要实现 resnet 的基本模块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Bottleneck (HybridBlock ): def __init__ (self, channels, strides, in_channels=0 ): super (Bottleneck, self ).__init__() self .body = HybridSequential(prefix="" ) self .body.add(nn.Conv2D(channels=channels // 4 , kernel_size=1 , strides=1 )) self .body.add(nn.BatchNorm()) self .body.add(nn.Activation('relu' )) self .body.add(nn.Conv2D(channels=channels // 4 , kernel_size=3 , strides=strides, padding=1 , use_bias=False , in_channels=channels // 4 )) self .body.add(nn.BatchNorm()) self .body.add(nn.Activation('relu' )) self .body.add(nn.Conv2D(channels, kernel_size=1 , strides=1 )) self .body.add(nn.BatchNorm()) self .downsample = nn.HybridSequential() self .downsample.add(nn.Conv2D(channels=channels, kernel_size=1 , strides=strides, use_bias=False , in_channels=in_channels)) self .downsample.add(nn.BatchNorm()) def hybrid_forward (self, F, x ): residual = self .downsample(x) x = self .body(x) x = F.Activation(residual + x, act_type="relu" ) return x
DilatedBottleneck DeepLab V3 和原始的 resnet 其中的一个不同点是 deeplab V3 的网络使用了 dialted conv,目的是为了使用更少的参数来 cover 到更大的 receptive field。在没有 dilated conv 的场景下,为了 cover 更大的 receptive field,通常有两个做法:1. 使用 pooling 操作,2. 使用更大的卷积核。Pooling 操作的存在的问题是损失和空间细节信息,这在 semantic segmentation 这种追求像素级精度的场景下不太合适;使用更大的卷积核导致网络的参数量增加,网络有过拟合的风险。因此,目前 dilated conv 在 semantic segmentation 领域非常流行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class DilatedBottleneck (HybridBlock ): def __init__ (self, channels, strides, dilation=2 , in_channels=0 ): super (DilatedBottleneck, self ).__init__() self .body = HybridSequential(prefix="dialted-conv" ) self .body.add(nn.Conv2D(channels=channels // 4 , kernel_size=1 , strides=1 )) self .body.add(nn.BatchNorm()) self .body.add(nn.Activation('relu' )) self .body.add(nn.Conv2D(channels=channels // 4 , kernel_size=3 , strides=strides, padding=dilation, dilation=dilation, use_bias=False , in_channels=channels // 4 )) self .body.add(nn.BatchNorm()) self .body.add(nn.Activation('relu' )) self .body.add(nn.Conv2D(channels, kernel_size=1 , strides=1 )) self .body.add(nn.BatchNorm()) def hybrid_forward (self, F, x ): residual = x x = self .body(x) x = F.Activation(residual + x, act_type="relu" ) return x
ASPP DeepLab V3 的 ASPP 和 PSPNet 中的略有不同,主要是有一个 global average pooling。global average pooling 的 kernel size 要根据具体的 feature map 大小进行调整。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class ASPP (HybridBlock ): def __init__ (self ): super (ASPP, self ).__init__(gap_kernel=56 ) self .aspp0 = nn.HybridSequential() self .aspp0.add(nn.Conv2D(channels=256 , kernel_size=1 , strides=1 , padding=0 )) self .aspp0.add(nn.BatchNorm()) self .aspp1 = self ._make_aspp(6 ) self .aspp2 = self ._make_aspp(12 ) self .aspp3 = self ._make_aspp(18 ) self .gap = nn.HybridSequential() self .gap.add(nn.AvgPool2D(pool_size=gap_kernel, strides=1 )) self .gap.add(nn.Conv2D(channels=256 , kernel_size=1 )) self .gap.add(nn.BatchNorm()) upsampling = nn.Conv2DTranspose(channels=256 , kernel_size=gap_kernel*2 , strides=gap_kernel, padding=gap_kernel/2 , weight_initializer=mx.init.Bilinear(), use_bias=False , groups=256 ) upsampling.collect_params().setattr ("lr_mult" , 0.0 ) self .gap.add(upsampling) self .concurent = gluon.contrib.nn.HybridConcurrent(axis=1 ) self .concurent.add(self .aspp0) self .concurent.add(self .aspp1) self .concurent.add(self .aspp2) self .concurent.add(self .aspp3) self .concurent.add(self .gap) self .fire = nn.HybridSequential() self .fire.add(nn.Conv2D(channels=256 , kernel_size=1 )) self .fire.add(nn.BatchNorm()) def hybrid_forward (self, F, x ): return self .fire(self .concurent(x)) def _make_aspp (self, dilation ): aspp = nn.HybridSequential() aspp.add(nn.Conv2D(channels=256 , kernel_size=3 , strides=1 , dilation=dilation, padding=dilation)) aspp.add(nn.BatchNorm()) return aspp
DeepLab V3 最后就是组合上述模块,实现 DeepLab V3。仍然有一个 deconv 实现双线性插值上采样的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def ResNetFCN (pretrained=False ): resnet = gluon.model_zoo.vision.resnet50_v1(pretrained=pretrained) net = nn.HybridSequential() for layer in resnet.features[:6 ]: net.add(layer) with net.name_scope(): net.add(Bottleneck(1024 , strides=2 , in_channels=512 )) for _ in range (6 ): net.add(DilatedBottleneck(channels=1024 , strides=1 , dilation=2 , in_channels=1024 )) net.add(nn.Conv2D(channels=2048 , kernel_size=1 , strides=1 , padding=0 )) for _ in range (3 ): net.add(DilatedBottleneck(channels=2048 , strides=1 , dilation=4 , in_channels=2048 )) net.add(ASPP()) upsampling = nn.Conv2DTranspose(channels=4 , kernel_size=32 , strides=16 , padding=8 , weight_initializer=mx.init.Bilinear(), use_bias=False , groups=4 ) upsampling.collect_params().setattr ("lr_mult" , 0.0 ) net.add(upsampling) net.add(nn.BatchNorm()) return net
DataIter Gluon 提供了一套更灵活的 feed 数据的接口,下面是语义分割中的一个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class DataIter (gluon.data.Dataset): def __init__ (self, images, labels, train=True ): self .data = images self .label = labels self .train = train def __getitem__ (self, idx ): if self .train: image, label = rand_crop(self .data[idx], self .label[idx]) return nd.array(image), nd.array(label) else : return nd.array(self .data[idx]), nd.array(self .label[idx]) def __len__ (self ): return self .data.shape[0 ]
训练 对网络进行初始化 1 2 3 4 5 6 7 8 ctx = [mx.gpu(i) for i in cfg.ctx] net = ResNetFCN(pretrained=True ) net.initialize(init=mx.init.MSRAPrelu()) net.collect_params().reset_ctx(ctx=ctx) if cfg.finetune: net.collect_params().load(cfg.base_param, ctx=ctx) net.hybridize() mx.nd.waitall()
定义相应的 DataIter 1 2 3 4 train_iter = DataIter(train_images, train_labels) val_iter = DataIter(val_images, val_labels) train_data = gluon.data.DataLoader(train_iter, cfg.batch_size, last_batch="discard" , shuffle=True ) val_data = gluon.data.DataLoader(val_iter, cfg.batch_size, last_batch="discard" )
定义 loss 和训练方法 1 2 loss = gluon.loss.SoftmaxCrossEntropyLoss(axis=1 ) trainer = gluon.Trainer(net.collect_params(), 'adam' , {'learning_rate' : cfg.lr})
tensorboard 通过 tensorboard 监控训练过程
1 2 train_writer = SummaryWriter(cfg.train_logdir) eval_writer = SummaryWriter(cfg.eval_logdir)
迭代训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 test_miou_list = [] for epoch in range (100000 ): for idx, batch in enumerate (train_data): data, label = batch data = gluon.utils.split_and_load(data, ctx) label = gluon.utils.split_and_load(label, ctx) losses = [] with mx.autograd.record(): outputs = [net(x) for x in data] losses = [loss(yhat, y) for yhat, y in zip (outputs, label)] for l in losses: l.backward() if count % 10 == 0 : mx.nd.waitall() trainer.step(cfg.batch_size) if count % cfg.test_interval == 0 : train_miou = np.array([IoU(yhat, y) for yhat, y in zip (outputs, label)]).mean() train_mloss = np.array([l.sum ().asscalar() for l in losses]).mean() eval_mloss, eval_miou = evaluate(net, val_data, loss, ctx) logging.info("epoch: %d\ttrain-loss: %f\ttrain-miou: %f\ttest-loss: %f\ttest-miou: %f" % (epoch, train_mloss, train_miou, eval_mloss, eval_miou)) train_writer.add_scalar("loss" , train_mloss, count) train_writer.add_scalar("miou" , train_miou, count) eval_writer.add_scalar("loss" , eval_mloss, count) eval_writer.add_scalar("miou" , eval_miou, count) net.collect_params().save(os.path.join(cfg.params_dir, str (count))) if len (test_miou_list) > 10 : test_miou_list.pop(0 ) test_miou_list.append(eval_miou) if max (test_miou_list) - min (test_miou_list) < 0.01 : lr = lr / 10.0 trainer.set_learning_rate(lr) count += 1
IoU 1 2 3 4 5 6 7 8 9 10 from __future__ import divisiondef IoU (yhat, y ): if isinstance (yhat, mx.nd.NDArray): yhat = yhat.asnumpy() if isinstance (y, mx.nd.NDArray): y = y.asnumpy() yhat = yhat.argmax(axis=1 ) a_and_b = np.sum ((y == yhat) * (y > 0 )) a_or_b = np.sum (((y > 0 ) + (yhat) > 0 )) return a_and_b / a_or_b if a_or_b > 0 else 0
评估算法 1 2 3 4 5 6 7 8 9 10 11 12 13 def evaluate (net, val_data, loss, ctx ): eval_loss, eval_iou = [], [] for idx, batch in enumerate (val_data): data, label = batch data = gluon.utils.split_and_load(data, ctx) label = gluon.utils.split_and_load(label, ctx) losses = [] with mx.autograd.record(train_mode=False ): outputs = [net(x) for x in data] losses = [loss(yhat, y) for yhat, y in zip (outputs, label)] eval_loss += [l.sum ().asscalar() for l in losses] eval_iou += [IoU(yhat, y) for yhat, y in zip (outputs, label)] return np.array(eval_loss).mean(), np.array(eval_iou).mean()
需要注意的点 因为 MXNet 使用了 lazy evaluation 策略,因此,在训练的过程中,我们至少需要每隔几个迭代要同步一次数据,否则前端不停地把计算 push 到后端,导致显存会爆掉。同步数据有多种方式,例如,上面训练代码中,for 循环中的 mx.nd.waitall() 是一种方式,还有通过消费计算结果,例如打印 loss 等来实现同步。数据同步也不能太频繁,否则影响计算效率。