Deep Knowledge Tracing
学情跟踪是一个比较典型的时间序列的数据分析和预测。其目的是根据之前的学习情况,对学生的学习情况进行建模。虽然这里描述的是学情跟踪建模,但是,接下来描述的算法同样适用于其它的类似的场景,例如股票涨跌情况预测。
在这一类应用场景中,与其它应用最重要的一个区别是,该类应用需要预测每一个输出位置的概率。例如,需要预测每一只股票的涨跌。而其它场景需要预测的一般都是 one hot 类型。
这里使用的是 LSTM, 具体的 LSTM 是什么或者 RNN 是什么不是这篇的目的。
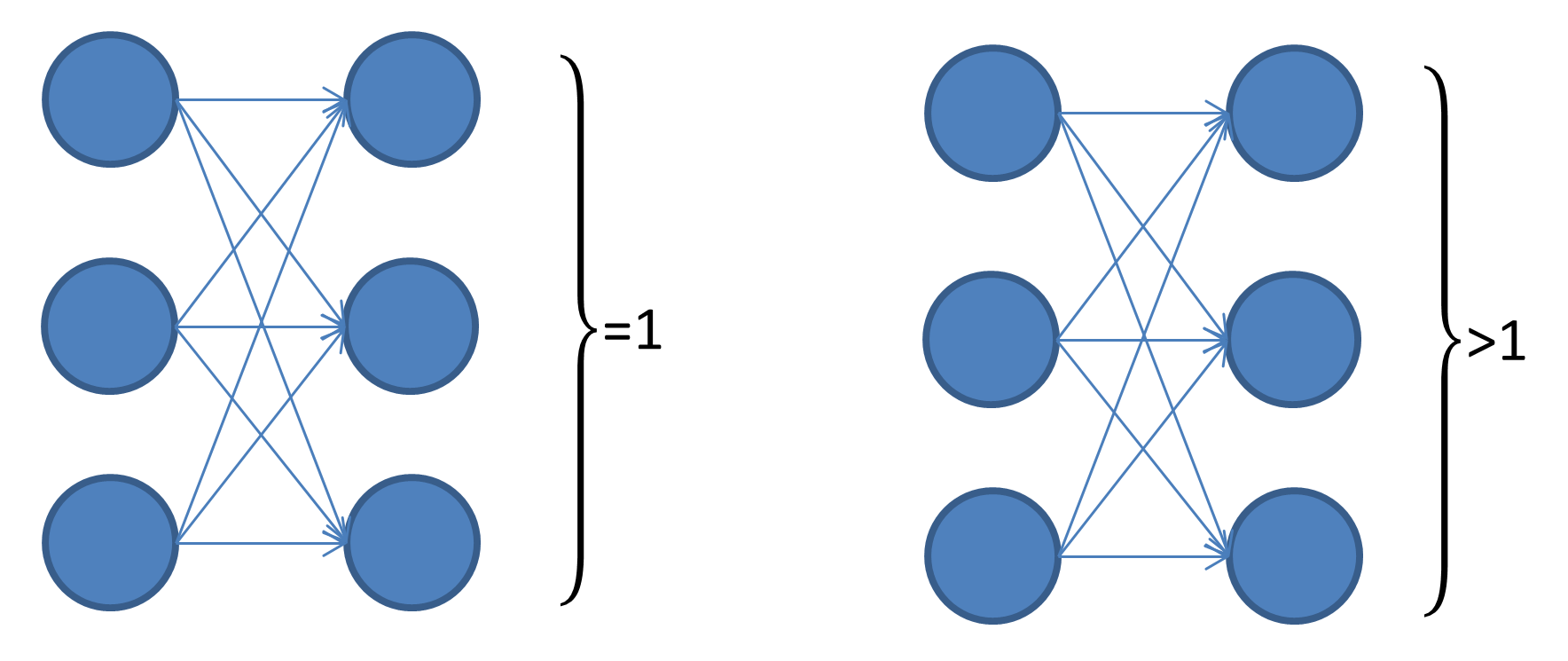
如下图左,输出节点使用 softmax 做映射,结果就是所有输出的和为 1. 如果输出节点记为 \(O_0,\cdots, O_{n-1}\), \(\sum_{i = 0}^{n-1} p\left (O_i\right)=1\). 下图右即为这里要讨论的情形,在每一个输出节点上分别使用 sigmoid 做映射,即对于任意一个输出节点,\(p (O_i = 0)+p (O_i = 1)=1\).
既然输出变了,那么,相应的 loss function 也会随之改变,就不能用常见的 softmax 的 cross entropy loss 了。在这里,使用的 sigmoid 二分类的 loss function. 具体的方法是有一点点小 trick 的。
另外,要解释一下输入数据,我们拿到的数据学生历史做题对错情况,那么对于输入,一个比较简单的编码就是取一个向量,假设共有 N 各题目,那么,向量的长度为 2N, 如果,在一个 timestep 上,表现为正 (做对题,股票涨等), 该向量的 第 i 各位置为 1, 其余为 0, 否则,第 i + N 位置为 1, 其余为 0.
输出节点个数是 N, 每一个节点表示的是这道题目做对的概率。
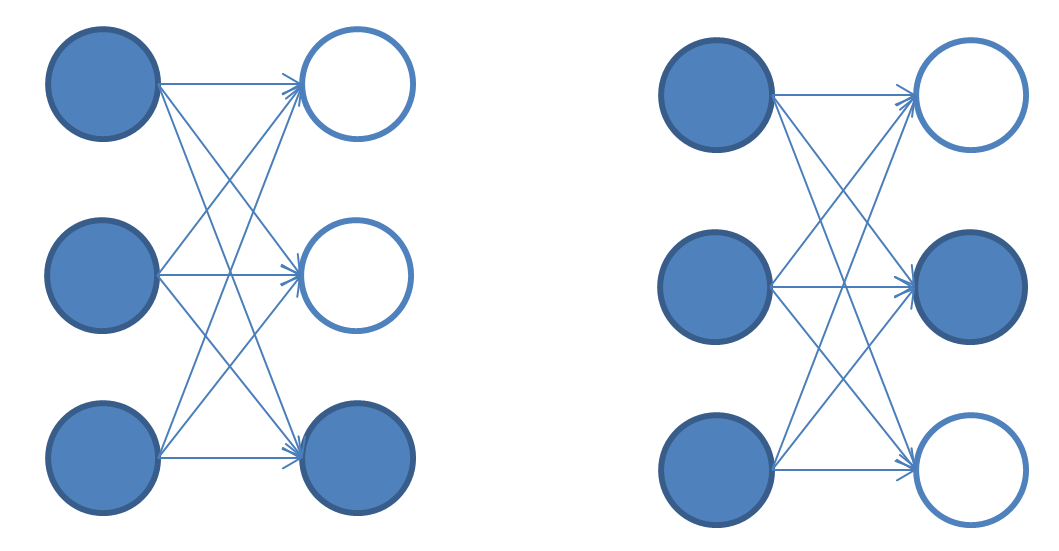
损失函数是这个工作中最最重要的地方,在每一次 forward 之后,会在相应的输出打上 mask, 例如,输入是第 i 只股票,那么,只看第 i 各输出节点,计算其 loss, 其它所有的节点都不看。如下图,第一次输入的是第 3 各学生的做题情况,那么,只激活第 3 各输出节点,第二次输入的是第 2 个学生的做题情况,那么,只激活第 2 个输出节点。
 \[
L = \sum_t l\left(y^T \sigma\left(q_{t+1}\right), a_{t+1}\right)
\]
\[
L = \sum_t l\left(y^T \sigma\left(q_{t+1}\right), a_{t+1}\right)
\]
其中,\(y^T\) 就是上面说到的 mask.
代码如下:
1 | import tensorflow as tf |