MXNet 和 tensorflow 都提供了完善的 Python 借口,Python 相对于 C++ 来多极其方便,因此 Python 比较多。深入分析了解 MXNet 的源码能够带来诸多好处,首先 MXNet 是遵循 C++11 标准的,使用了大量的 C++11 的新特性,分析 MXNet 源码可以帮助学习 C++11 的新特性。其次,MXNet 遵循了模块化的系统设计思想,整个系统设计非常完善,并且和 tensorflow 相比,MXNet 的代码量要少很多,分析 MXNet 的源码可以帮助学习设计简洁高效的系统。
为什么选择 MXNet
tensorflow 已经成为了事实上的深度学习框架的主流,Google 也在不遗余力地推广,对于大部分人来说选择分析 tensorflow 源码更合理。而之所以选择 MXNet, 其中最重要的原因就是 MXNet 的代码量比 tensorflow 要少很多。然而,MXNet 代码写的相当飘逸,事实上,这个过程中似乎并没有节省很多时间。
在 14 年最后一份实习的时候,开始使用 CNN 做图像方面的工作,当时很自然而然的选择了 Caffe, 在初期,Caffe 的确可以满足绝大部分的任务需求。Caffe 的源码结构清晰,代码简单,确也可以完成大部分的任务需求。但是,后来随着网络结构设计地越来越复杂,Caffe 渐渐地无法满足需求了。在经历了长时间的对 Caffe 修修改改之后,最终入了 MXNet 的坑。MXNet Python 接口,可以很方便地完成网络的构建,例如我用 MXNet 写的 residual network 只有不到 50 行,但是,用 Caffe 写的的网络定义文件有 6000 多行。
MXNet 总览
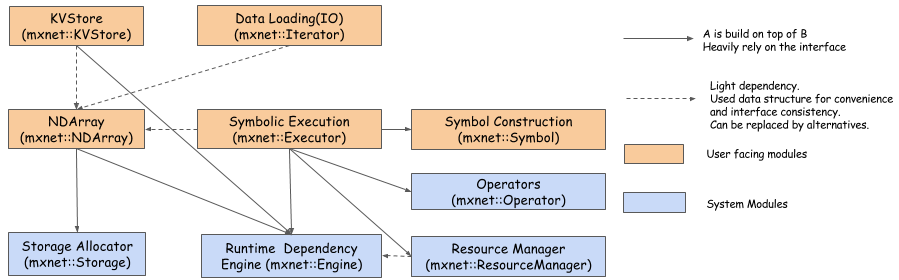
上图显示了 MXNet 各个模块之间的关系。最新的 MXNet 与上图有一些区别,主要是 nnvm 的引入。各个模块的作用如下:
- KVStore: 提供了 key-value 的存储接口,实现数据的快速同步。同时支持单机模式和分布式模式
- Data Loading(IO): 数据 IO, 这个模块主要目的是实现非常高效且分布式的数据加载和预处理。MXNet 中支持其它格式如
numpy.array的数据输入,但是,该模块可以使得 load 数据更加高效。因为,在深度学习中,高效的数据载入方法可以避免 GPU 空载,提高 GPU 的利用率。例如,在 CNN 中,一个 batch 通常要以随机的顺序读取非常多的小图片,因此,数据载入就要花费大量时间,通常在当前 batch 计算完成之后,下一个 batch 需要的数据还没有准备好。 - NDArray: 动态异步的 n 维 array, 部分功能可以类比
numpy. 另外比较重要的是,NDArray 同时支持在 CPU 和 GPU 上计算。该模块提供了命令式的编程 (对比的,Symbol 提供了符号式编程) - Symbolic Execution: 静态图引擎,主要是提供高效的图的执行和优化。例如 memory 的优化,数据的绑定和检查都是在这一模块中完成的。
- Symbol Construction: 提供从 Symbol 构建 computation graph 的方法。例如,graph 的 topo 序计算,从而得到唯一的图中 node topo 顺序就是在该模块完成。
- Operator: 具体的各种操作,可以类比 tensorflow 中的 kernel 和 caffe 中的 layer, 绝大部分任务只需要修改或者增加相应的 operator 就可以完成。
- Storage Allocator: memory 管理模块,包括 memory 的申请和复用。
- Runtime Dependency Engine: 计算的调度模块,例如同步还是异步,要不要使用线程池模式,在 CPU 还是在 GPU 上计算,都是该模块来完成的。
- Resource Manager: 资源管理模块,例如,随机数的生成,临时 memory 的管理等。
上面说到的 nnvm 主要是和 Symbolic Execution 和 Symbol Construction 有关。