MobileNet 是 Google 提出的一种 efficient 的模型,总结来讲,mobilenet 中没有全新的 layer, 因此,完全可以在现有的框架例如 caffe, mxnet, TensorFlow 中非常方便地实现。
mobilenet 这篇文章感觉还是堆试验堆出来的,文章中给出了各种数据集上的实验结果。Google 还是财大气粗。
mobilenet 简单来讲,主要还是利用了和 xception 中类似的 depthwise separable conv, 把标准的 conv 操作拆解成一个 depthwise 的 conv 和一个 pointwise 的 conv, 也就是把 spatial 维度的信息提取和 depth 维度的信息融合分来来做。mobilenet 能够 efficient 的原因是在 depthwise conv 中对于每一个 channel 使用 1 个 conv kernel 去提取特征。这样,mobilenet 的主要计算量在 pointwise conv, 而我们知道,pointwise conv 的计算可以转换成一个 GEMM 操作。而 GEMM 是一个 heavily optimized numerical linear algebra algorithm. 因此,mobilenet 计算的时候速度非常快。当然,由于 depthwise separable conv, 参数量也变小了。
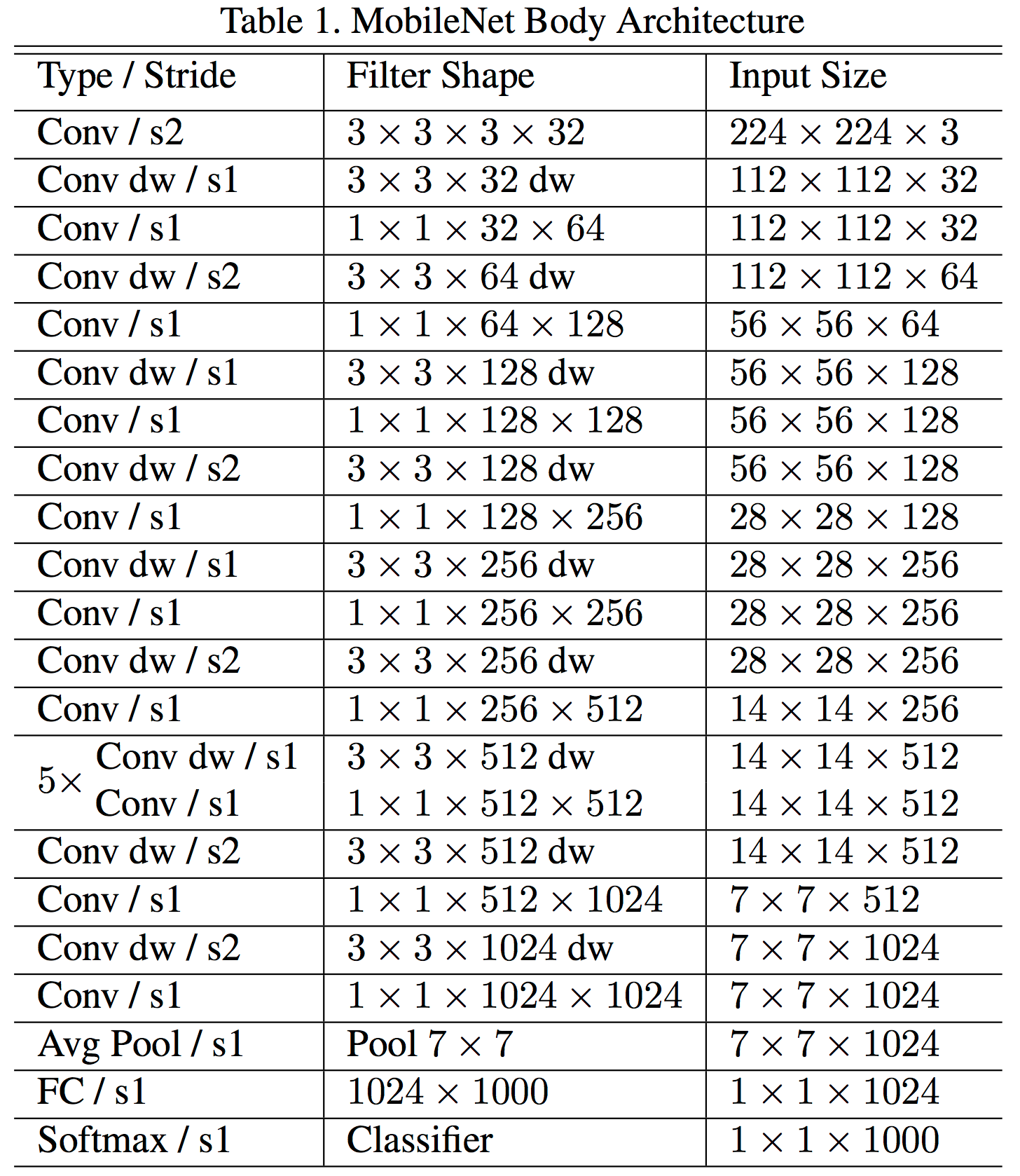
上面的表格是 mobilenet 的结构,从中可以看出,全程 pooling 操作,download sampling 是通过 strided conv 来完成的。在 depthwise conv 中没有改变 feature map 的 depth, 即输入时 N 个 channel, 那么每个 channel 使用一个二维卷积去操作,把结果 concat 到一起。之后可以使用 pointwise conv 融合 depth 维度上的信息。depth 数量的改变也都是在这里完成的。

Width Multiplier and Resolution Multiplier
接下来就是大量的试验探索了网络的宽度和输入图像的大小对模型精度和计算量的影响。没啥特别高的价值。