Faster RCNN 的工作具有里程碑的意义,把 Region Proposal 和具体的检测过程全部通过 CNN 完成,实现了整个目标检测过程的 end to end 的训练。后续的大部分工作,例如 SSD, RFCN,FPN,Mask RCNN 等都延续了 RPN 的思路,因此,充分理解 Faster RCNN 对后续的工作有很多帮助。
整体过程
RPN 的引入使得 Faster RCNN 的网络结构有一点点复杂,尤其是分别有两次 BBox regression 和 classification,导致一眼看上去会有点懵。
整体上来看,Faster RCNN 输入一张图像,期望的输出是:
- 图像中所有目标的 BBox;
- 对于每一个 BBox,需要输出一个对应的 label,表明该 BBox 里面的是什么目标;
- 对于每一个 label 和 BBox 还需要输出概率,表明模型的置信度。
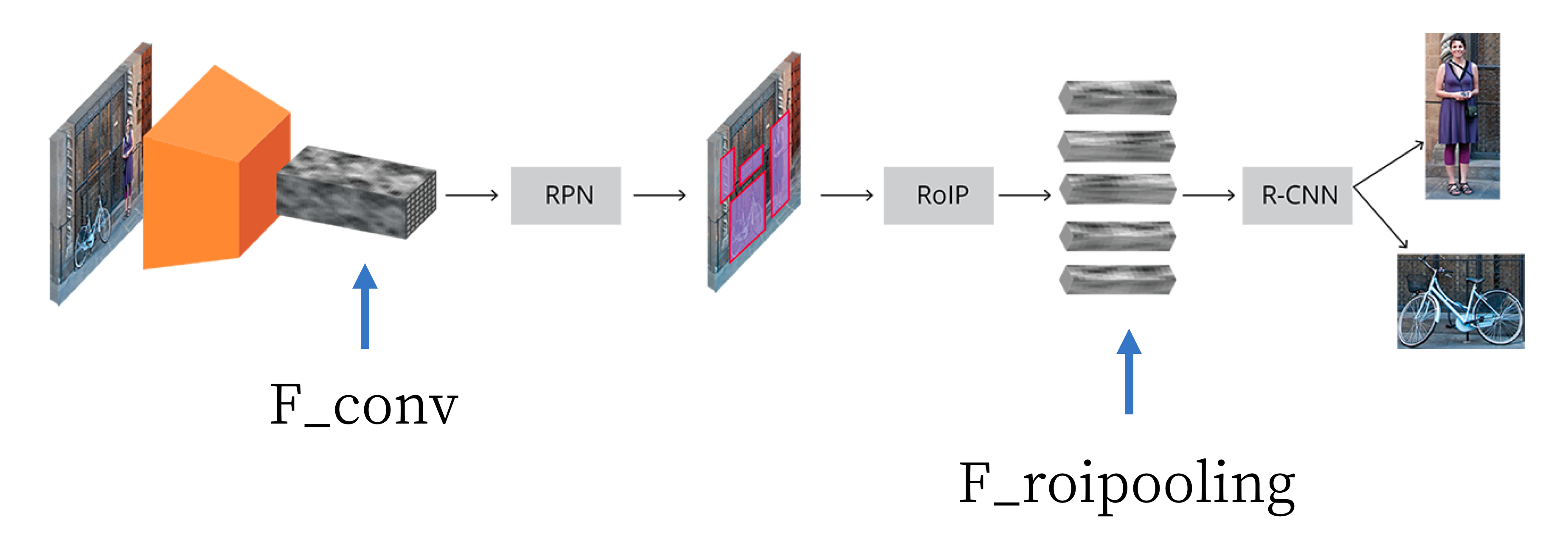
简单来说,要经历以下 3 个步骤:
第一步,输入图像表示为 \(H \times W \times D\) 的矩阵。图像首先输入到 CNN 中进行前向传播,得到 feature map,即上图中的 F_conv,在 F_conv 之前和普通的 CNN 没有任何区别,主要变化的是 F_conv 之后的部分;
第二步,把 F_conv 输入到 RPN 网络中,RPN 的作用是得到 预先定义好数量的 区域,这里得到的预先定义好数量的区域就是通过 RPN 得到的 Proposal BBox(替代 selective search 的工作)。
第三步,第二步得到了 Proposal BBox,接下去就是在这些 Proposal BBox 的基础上得到最终的精确的 BBox 以及每个 BBox 中的目标类别,过程和 Fast RCNN 基本上是一模一样的。
Stage 1:RPN 获取 Proposal BBox
RPN 的作用是替代 selective search 给出 Proposal BBox。其基本过程是:
- 人为并且先验地 给出一些 BBox(文章中称为 Anchor),这些 BBox 很不靠谱,而且数量非常多;
- 在 #1 中的 BBox(Anchor) 基础上进行调整和过滤,得到数量数量合理的、并且比 #1 靠谱一些的 BBox,作为 Proposal BBox。
接下来要分别解释上述两个步骤。
给出 Anchor
检测的目的是找到 BBox。每个目标物体的 BBox 通常有不同的大小和长宽比。假设我们知道需要预测的图像中有 2 个目标,那么,直接让网络输出两组 BBox 的坐标就好了,即 \(x_{min}\), \(y_{min}\), \(x_{max}\), \(y_{max}\). 但是,这种输出定义至少有两个方面的问题,
- 输入的大小和长宽比变化很大,导致从某种意义上说输出的内容不是同一个尺度
- 在这种输出中,必须要限制 \(x_{min}<x_{max}\), \(y_{min}<y_{max}\), 这在神经网络中比较难搞定。
因此,通常采用另外一种方式:不去直接学习 BBox 的具体坐标,而是学习 BBox 相对于 reference BBox 的 offset(这种给个 reference 的思想是不是和 ResNet 中的 shortcut 有点类似?)。假设 reference 的位置表示为 \(x_{center}\), \(y_{center}\), \(width\), \(height\), 那么,我们让网络去学习 \(\Delta{x_{center}}\), \(\Delta{y_{center}}\), \(\Delta{width}\), \(\Delta{height}\).
下面说回 Anchor,Anchor 实际上就是上面说的 reference BBox,并且是完全人为地拍脑袋决定的 reference BBox,完全不涉及到学习过程。现在具体解释一下这个拍脑袋的过程:
假设 F_conv 的 channel 数是 \(d\),那么,F_conv 的 shape 应该是 \(W/r \times D/r \times d\),其中 \(r\) 是 subsampling rate。为方便,F_conv 的 shape 记为 \(w \times h \times d\)。RPN 的第一步是在\(w \times h\) 的每一个位置上去生成 \(k\) 个 Anchor,现在的问题是:每一个位置的 \(k\) 个 Anchor 是怎么生成的?答案是:拍脑袋生成的,Anchor 既然是 BBox,那么,就可以有不同的大小和长宽比,原文中选了 3 种不同的大小和 3 种不同的长宽比,组合一下可以得到 \(3 \times 3=9\) 个不同的 Anchor。
因此,一张输入图像生成的 Anchor 数量是 \(w \times h \times k\)。
给出 Proposal BBox
不靠谱的 BBox(即 Anchor)给出来了,接下来就是如何从这些不靠谱的,数量非常多的 BBox 中给出一些相对来说靠谱一些,并且数量不是那么多的 Proposal BBox。
回顾一下目前的状态,在 F_conv 的 \(w \times h\) 个位置上,每一个位置上的 depth 是 \(d\),相当于一个 \(d\) 维的向量,每一个位置上对应地生成了 \(k\) 个 Anchor。
这里要做的工作就是,对于每一个位置,通过这 \(d\) 维的向量,去调整(和过滤)它对应的 \(k\) 个 Anchor,得到靠谱一些的 Anchor,作为 Proposal BBox。
具体方法其实是比较野蛮粗暴的。直接在这 256 维的向量上引出 2 个 全连接层(FC),其中一个 FC 用来判断 Anchor 中是目标还是背景(二分类任务),另外一个 FC 用来在 Anchor 上回归出如果要得到稍微靠谱的 BBox 要如何进行的,即学习 \(\Delta{x_{center}}\), \(\Delta{y_{center}}\), \(\Delta{width}\), \(\Delta{height}\)。

搞定这一步之后,就完成了对于 Anchor 中是目标还是背景的判定以及如何调整 Anchor 使得其表示的 BBox 变得靠谱一些。
可是,上面只是完成了对于 F_conv 上一个位置的判定,F_conv 有 \(w \times h\) 个位置,因此要对每一个位置进行相同的判定。实际工程实现中是使用 \(1 \times 1\) 的卷积操作完成的。
接下来是一些后处理工作,包括:
- 对于上面被判断为背景的 Anchor,直接过滤掉;
- Anchor 中有一些是 overlap 的,要通过 nms 进行合并。
至此,完成了 Proposal BBox 的工作。接下来,就是和 Fast RCNN 完全相同的精修 BBox 以及识别 BBox 中具体是哪类目标的过程。
Stage 2:精修 BBox 以及识别目标的具体类别
Stage 1 的 RPN 给了还是不太精确的 Proposal BBox。那么,对于 Stage 2 的精修 BBox 和识别具体目标这个任务,一个简单的想法是把 Proposal BBox 从原图中抠出来,resize 到固定长宽尺寸,然后输入到一个 CNN 中去做具体类别识别和 BBox 精修。但是,这种方法又要过一遍 CNN 提取特征的过程,该过程计算量很大。在上面的 RPN 过程中,F_conv 已经有提取的特征了,是否可以复用 F_conv 的特征呢?
首先考虑一下直接使用 F_conv 的阻力。在 RCNN 中之所以把 Proposal BBox resize 到 fixed size 的 image 然后 feed 到 CNN 中,是因为在 classification 和 regression 的两个 branch 中均有 FC 操作,而 FC 操作要求输入的 shape 必须是 fixed 的。如果要复用 F_conv 的结果,必须保证在输入到 classification 和 regression 的所有的 patch 必须是 fixed size 的。
一种方法是,从 F_conv crop 出 Proposal BBox 对应的 feature map 然后 resize 到 fixed size 输入到后续网络中。另一种方法,也是 Faster RCNN 采用的方法是对 Proposal BBox 对应的 F_conv 区域进行 ROIPooling,然后把 ROIPooling 的结果 feed 到后续网络中。(ROIPooling 可以确保输入不同尺寸的 feature map,输出固定尺寸的 feature map)
后续过程和 RPN 类似,只不过 classification 部分不是判断背景/目标的二分类任务,而是判断具体是什么目标的多分类任务(N+1,N 是类别数,1 是背景)。然后是去除被判定为背景的 BBox 以及 NMS 过程。
后注
Anchor 的选择其实也并不是完全拍脑袋,还是要根据具体检测的目标特点去选择,例如,检测行人,可以选一些瘦长的 BBox。同时还可以根据数据的统计特定来确定,例如,需要检测的目标大小均在 \(50 \times 50\) 像素以上,那么就没必要选太小的尺度。
为容易理解,上面的 RPN 网络做了简化,实践中使用的要稍微复杂一点,但是思路不变。