本篇记录下我使用使用深度学习做图片检索的过程。
任务背景:有很多图片,而且这些图片没有”类”的概念,也可以说我的每一类都只有一张图片。所以,这种情况下不能用常见的基于”识别”的图像检索。在此之前,使用 Bag of Visual Words 的方法做出了一个版本,可以参考这篇.
想法来源
这个方法的灵感来源于 Google 的 FaceNet, 使用 triplet loss 直接优化图片特征的距离。因为,不需要图片的 label 信息,我们不需要标注任何数据。这就比较适合没有标注的数据。另一方面,因为每一“类”图片都只有一张,因此,我对每一张图片做了 data augmentation. 这样,每一“类”图片中就有了多个 sample.
Overview
具体的过程如下图所示:
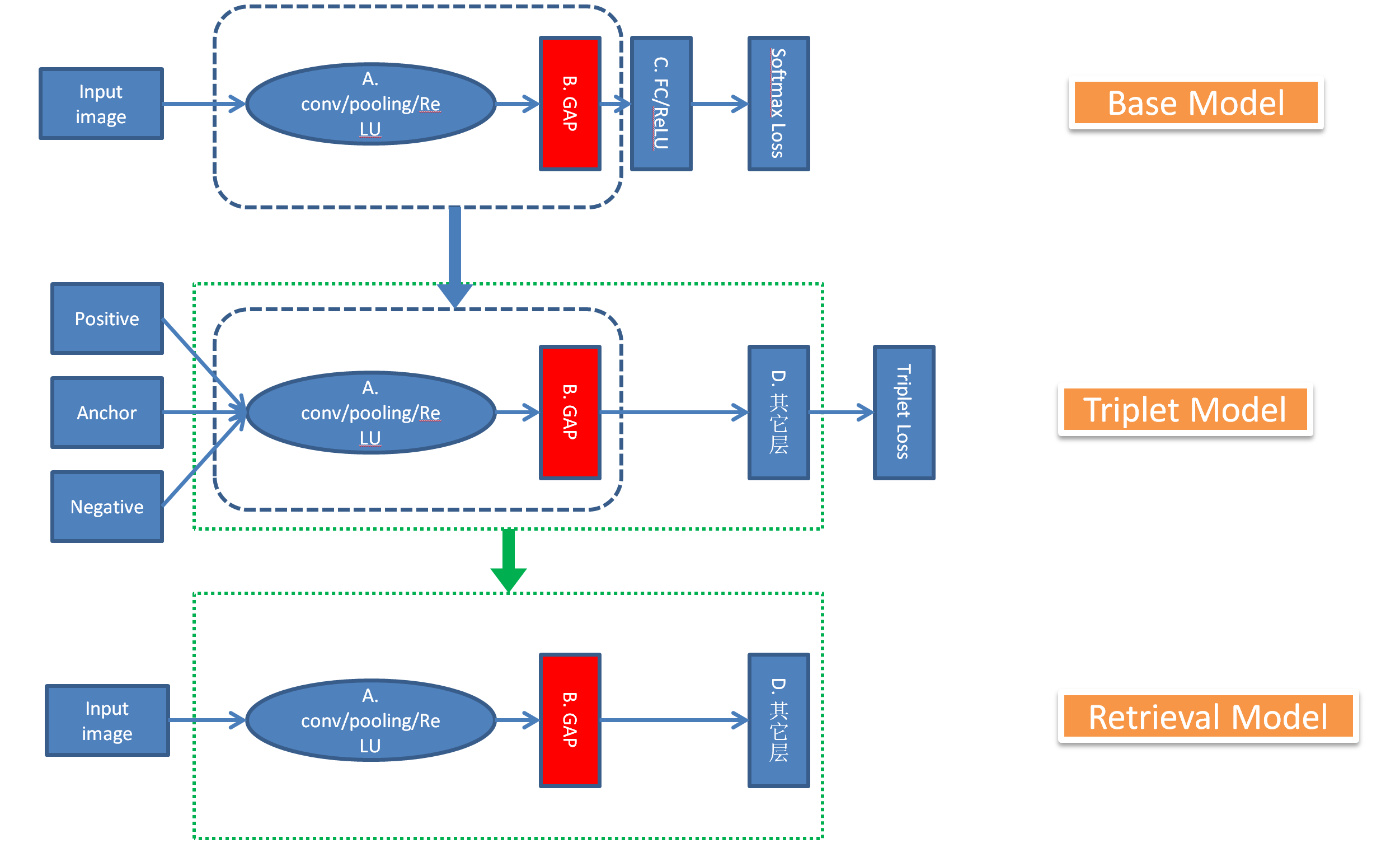
训练模型分为 3 个步骤:
- 获取一个 Base Model
- Transfer Base Model 训练 Triplet Model
- 把训练好的 Triplet Model 整理成用来获取图片特征的 Retrieval Model
Triplet Loss
Triplet Loss 的想法很简单:类内距离小,类间距离大。
\[ \left\|f\left(x_i^a\right)-f(x_i^p) \right\|_2^2+\alpha < \left\| f\left(x_i^a\right)-f\left(x_i^n\right) \right\|_2^2 \]其中,\(f(x) \in R^d\) 是图片 \(x\) 到特征空间 \(R^d\) 的映射。
\(x_i^a\), \(x_i^p\) 是同一张图片通过 data augmentation 得到的图片 forward 之后的向量
\(x_i^n\) 是 另外一张不同的图片或其 augmentation 之后的图片 forward 之后的向量
\(\alpha\) 是 margin, 正数,在实验中我使用的是 margin = 1
Base Model
Base Model 是一个图像识别的模型,例如 VGG16 等,在这个模型的基础上做的 transfer learning. 理论上讲,不做 transfer learning, 直接使用 triplet learning 也可以完成训练的目的,但是,在实验中,我发现,使用 transfer learning 至少有两个好处:
- 网络收敛速度更快
- 最终训练到的 triplet model 的抽象能力更强。
关于第二点,我的想法是,直接使用 triplet 训练的话,模型基本上还是非常 naviely 地去寻找 low level 的特征。而从一个识别模型 transfer 训练的话,因为识别模型具有高度的抽象能力,所以,可以说,triplet model 一出生就具备了很强的抽象能力。这一点,也体现在了实验结果上面。
代码实现
代码实现分为两个步骤,第一步是获取预训练的模型,使用与训练模型初始化 Triplet Model 的网络参数,和普通的 transfer learning 并没有什么差别,第二步使用 Triplet Loss 来优化 Triplet Model.
获取 Base Model
Base Model 这里使用的是 VGG16, 当然也可以使用其它的模型。我之所以使用识别模型作为 Base Model, 一方面是因为识别模型比较容易找得到,另外一方面,识别模型能对输入数据的抽象能力更好。实验中首先使用 VGG16 的识别模型作为 Base Model, 确认和该方法有效。具体的模型转换方法参考另外一篇文章. 最终选用的是 Residual Network 的模型。
训练 Triplet Model
第一步,修改 VGG16 的模型,使之可以接受 3 各输入节点。方法如下:
1 | same = mx.sym.Variable('same') |
然后从 concat 开始做正常的 forward 就可以了。
第二步是 Triplet Loss 的改造,还是用代码来解释:
1 | # margin |
完整的代码在Github
总结
整个过程还是比较明确的,triplet 的方法也比较容易想得到,尤其是看过 FaceNet 的论文之后。使用这种方法的效果还是非常惊艳的,准确率以及搜索结果的可解释性全面吊打 BoVW 的方法。