搜图的一般过程是首先对于数据库中的所有图片提取并且保存特征,当 Query 输入之后,按照相同的方法提取特征,然后,拿 Query feature 去数据库中按照最近邻的方法去搜索。在最近邻算法中,距离经常采用欧几里得距离。当数据库中的图片量非常大,例如上百万之后,采用欧几里得距离的最近邻算法速度就会比较慢。这时,常用的方法是使用 binary code 来 represent 一张图片。使用 binary code 的好处是,可以使用 Hamming distance 来计算两张图片的相似性.(Hamming distance 的计算方法是对两个向量做异或操作). 这篇文章的工作是:能否直接从图片中生成 binary compact code.
Supervised Semantic-preserving Deep Hash
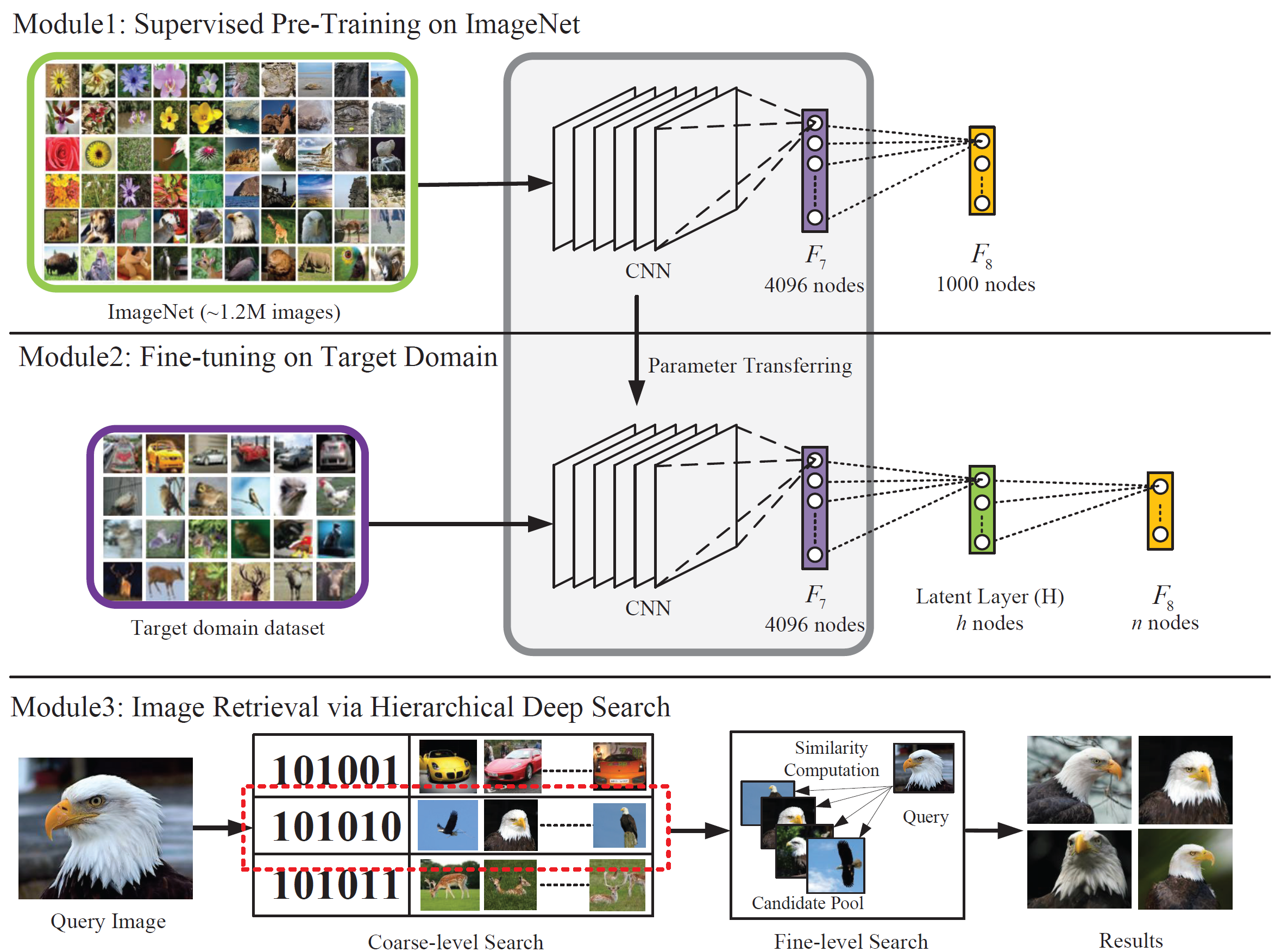
假设图片的分类结果完全依赖于图片的 hidden attribute, 这这个属性中的每一个元素要么是 on 的状态,要么是 off 的状态。那么,目标就是学习到图片的这个 hidden attribute, 然后,这个 hidden attribute 就可以作为 binary code 使用了。具体做法如下:
在\(F_7\) 和 \(F_8\) 中间插入一个 hidden layer(\(H\)), \(H\) 的 activation function 是 \(sigmoid\)
\(H\) 和 \(F_8\) 随机初始化,其他 layer 使用通过 ImageNet 训练的参数来初始化
Finetune
Image Retrieval via Hierarchical Deep Search
Coarse-level Search
给定一张图片 \(I\), 计算这张图片的 \(H\) 层的输出 \(Out(H)\). 通过下面的计算方法获取对应的 binary code.
$$ H^j= \begin{cases} 1 & out^j(H) \geq 0.5 \\ 0 & otherwise \end{cases} $$通过 Hamming distance 找到一组相似结果,然后通过精细匹配得到最终结果。
Fine-level Search
精细匹配使用的是 \(F_7\) 的输出,使用欧几里得距离:
$$ s_i=\left\|V_q - V_i^P\right\| $$总结
这篇文章实在做基于深度学习的图像检索的调研中看到的一篇思路比较简单的方法,但是在实际实验中,并没有达到我想要的效果,o(╯□╰)o 在实践中效果比较好的使用深度学习进行图片检索的实践请参考另外一篇.